
Подробные консультации (платные) по этим вопросам можно получить по электронным каналам связи (Skype, Zoom, телефон и т.п.) или в офисе компании в Казани (по предварительной записи) - оставьте заявку и напишите нам свой вопрос
При необходимости - обращайтесь к нам!
Оплатить консультацию по вопросу можно здесь
Заказать консультацию или сделать заявку на обучение можно:
- или через форму обратной связи
- или через форму контактов внизу страницы
- или опишите кратко суть Вашего проекта (это уменьшит количество уточняющих вопросов)
Мы можем помочь Вам законно снизить налоги.
Путем применения законных налоговых льгот и преференций (по НК РФ и региональным законам - субъектов РФ):
- проверка (подходят ли Ваши компании под какие-либо)
- подготовка компании для применения налоговых льгот
- иногда - реструктуризация компании
- иногда выделение раздельного учета операций внутри компании
Мы можем помочь Вам получить льготные деньги:
Путем участия в программах и конкурсных отборах (по ППРФ и региональным НПА):
- субсидии
- гранты
- целевые бюджетные средства
- льготные займы фондов
- льготные кредиты банков
- земельные участки без торгов
- льготные ставки аренды земли и имущества
При необходимости - обращайтесь к нам!
По теме поддержки бизнеса в условиях внешнего санкционного давления:
- 2022 Импортозамещение в ИТ-отрасли 2.0
- 2022 Ситуация в ИТ-отрасли в условиях санкций
- 2022 новый грант РФРИТ: 20 - 6 000 млн руб 80% сметы
- 2022 приоритеты грантов РФРИТ, ФСИ, Сколково
- IT-компании мораторий 2022-2024 на плановые проверки
- IT-компаниям намерены предоставлять льготные кредиты
- IT-специалисты получат отсрочку от армии
- Бюджет на создание репозитория Open Source (аналог GitHub)
- Вопросы и ответы по мерам поддержки ИТ-отрасли март 2022
- Меры поддержки ИТ-сферы март 2022
- 2022 компенсация 50% стоимости покупаемых лицензий ПО
- 2022 Меры поддержки ФП «Искусственный интеллект»
- 2022 Импортозамещение в ИТ-отрасли 2.0 таблицей
- 2022 Каталог совместимости российского ПО
- 2022 Меры поддержки отечественной электроники
- 2022 Приоритеты разработки и внедрения отечественного ПО
- 2022 Ситуация в ИТ-отрасли в условиях санкций
- 2022 Что изменится в налогах ИТ-компаний в 2022 году?
- 2022 год ИТ-компании получили новые налоговые льготы
- 2022 предустановка и защита российского ПО
- 2022 приоритеты грантов РФРИТ, ФСИ, Сколково
На сайте Ассоциации разработчиков программного обеспечения «Отечественный софт» появились разделы «Российское ПО для импортозамещения»:
- Импортозамещение: Список иностранный продукт - отечественный продукт
- Импортозамещение: Таблица иностранный продукт - отечественный продукт
- Каталог совместимости российского программного обеспечения
Еще по теме поддержки в условиях санкционного давления в других сферах:
- Перечень мер поддержки бизнеса в условиях внешнего санкционного давления:
- Антикризисная поддержка субъектов МСП
- Меры поддержки ИТ-сферы март 2022
- Перечень мер поддержки МСП в период пандемии
- 2022 Импортозамещение в ИТ-отрасли 2.0 таблицей
- 2022 Каталог совместимости российского ПО
Классы ПО, критичные для экономики и невоспроизводимые в рамках обычного рыночного механизма
- Балансировщики нагрузки (VMWare)
- Диспетчеризация SCADA, HMI и IIoT-app интеграции с ERP
- Машинное обучение (ML)
- ПО для управления производственными процессами (MES, EAM)
- Продуктовая линейка графического дизайна
- Публичный репозиторий кода и бинарных артефактов (GitHub)
- Разработка BIOS, драйверов периферийного оборудования
- Связующее ПО, EDP системы (корпоративная платформа данных)
- Система комплексного мониторинга управления компонентов ИТ-инфраструктуры (SharxBase)
- Система управления имущественным комплексом, предприятием ERP
- Системы управления обучением, обучающим контентом LMS
- Системы управления цепочками поставок, включая мультимодальную TMS
- Средства автоматизированного проектирования (CAD)
- Средства инженерного анализа (CAE)
- Средства разработки ПО
- Средства распознавания символов и работы с документами PDF
- Средства управления жизненным циклом изделия (PLM)
- открытые форматы документов и протоколы обмена ODF
Методические рекомендации для заявок на включение российского ПО в Единый реестр
- Актуализация информации на официальном сайте ПО
- Информация о процессах разработки и поддержки ПО
- Наличие необходимых лицензий на ПО
- Определение класса по единому классификатору ПО
- Подготовка проверочного экземпляра ПО
- Проверка «юридической чистоты» Минкомсвязи
- Проверка технологического стека ПО Минкомсвязи
Чем еще мы можем быть Вам полезны:
- разовые консультации по подготовке к конкурсам,
- экспертиза разработанных (своими силами) документов и заполненных форм заявки,
- доработка документов и форм заявки,
- разработка сметы проекта, финансовой модели, бизнес-плана, технико-экономического обоснования (ТЭО), меморандума, презентации, паспорта проекта, подготовка пакета документации по проекту,
- консультации по налогообложению гранта, бюджетным, казначейским процедурам, методике раздельного учета, отчетности, иным финансово-экономическим, маркетинговым вопросам
- получение целевого финансирования, налоговых льгот, грантов и субсидий, иных видов поддержки, источникам финансирования
- сопровождение проекта заявителя в конкурсах региональных и федеральных органов власти,
- проведение исследований рынка (маркетинговых), оценка конкурентов, рекомендации по продвижению, развитию,
- многое другое - обращайтесь к нам за услугами и консультациями.
Подробности для самостоятельного чтения:
- Методика раздельного учета расходов субсидии РФРИТ
- Обязательства грантополучателя РФРИТ
- Ответы на часто задаваемые вопросы РФРИТ ППРФ 550
- 2021 Меры поддержки ФП «Искусственный интеллект»
- 2021 Приоритеты разработки внедрения отечественного ПО
- Включить изделие в реестр радиоэлектронного оборудования
- Внести программный продукт в реестр российского ПО
- Войти в реестр разработчиков электроники
- Антикризисный план
- Как подготовить свой проект, структуру бизнеса - для привлечения гос.поддержки (целевые бюджетные средства, субсидии, налоговые льготы, гранты, преференции и т.п.) или для привлечения заемного финансирования, выхода на IPO
- IT-система поддержки инновационной деятельности МЭР РФ
- Акселератор АСИ проекты развития технологий, качества жизни и самореализации
- Расчеты эффективности внедрения ИТ решений в бизнесе
- Что нужно знать ИТ компаниям про льготы, субсидии,преференции?
- Что такое проектный учет? Где применяется?
- Возмещение затрат производителям аудиовизуальной продукции
- 14% страховые взносы производителям анимационной аудиовизуальной продукции
- Субсидии на продвижение аудиовизуальной продукции
- Налоговые льготы для разработчиков отечественного ПО для ЭВМ, аппаратно-программных комплектов (АПК\ПАК), радиоэлектроники
- 2022 Меры поддержки ФП «Искусственный интеллект»
- Субсидии ППРФ 456
- Стартапы ИИ и IT-компании
- Субсидии ППРФ 767 пилотным проектам апробации ИИ
- Льготы для IT-компаний в 2021: кому и как?
- Методика расчета ССЧ
- Налог на прибыль 3% в бюджет РФ, 0% в бюджет региона
- Не облагаются НДС операции с ПО ЭВМ и БД из реестра
- Нулевая 0 ставка НДС с 2021 года по продаже прав на ПО
- О льготах ИТ компаниям с 2021 года Минфин
- О налоговых льготах для IT-отрасли с 2021 года
- Расчет 2021 страховых взносов для IT (7,6%*)
- С 2021 года тарифы страховых взносов для IT-компаний
- Снижены тарифы страховых взносов до 7,6%
- Ставка по налогу на прибыль 3 процента ИТ компаний
- Стоимость ЭВМ через амортизацию - НЕ единовременно
- Страховые взносы 7,6% с 2021 года для ИТ, РАВП, ИЦ, СЭЗ, ОЭЗ, ТОСЭР
- Страховые взносы 7,6% с 2021 года для организаций ИТ
- Упрощение въезда иностранцев для ИТ-компаний
- 1% и 5% ставки УСНО резиденту ОЭЗ Иннополис 62, 63 код
Роспатент запустил новую цифровую платформу для доступа граждан и организаций к накопленным массивам мирового патентного фонда.
На платформе реализованы:
- поиск сведений по мировому фонду изобретений и полезных моделей
- многоязычный полнотекстовый и атрибутивный поиск на основных европейских языках
- поиск на основе патентных классификаторов
- поиск по химическим формулам, генетическим последовательностям
- для разработчиков реализован программный интерфейс API.
Пример найденного патента по запросу ML AI
Реферат
Изобретение относится к средствам распределенного обучения модели машинного обучения (ML) искусственного интеллекта (AI). Технический результат состоит в повышении качества обучения персонализированных моделей ML при предотвращении их «переобучения» и при сниженных затратах на передачу данных по сетевым соединениям. Способ содержит этапы, на которых: инициализируют одну или более моделей ML на сервере, распространяют одну или более моделей ML среди одного или более пользовательских устройств (UE), соединенных с сервером, накапливают данные, формируемые пользователем, передают обучающие данные с сервера на одно или более UE, осуществляют обучение модели ML на основании собранных данных и обучающих данных, получают на сервере обученные модели ML, обновляют на сервере модель ML путем усреднения обученных моделей ML, полученных от одного или более пользовательских устройств, и передают обновленные модели ML в одно или более UE. Система реализует описанный способ с использованием машиночитаемого носителя. 3 н. и 10 з.п. ф-лы, 3 ил.
Формула изобретения
1. Способ распределенного обучения модели машинного обучения (ML) искусственного интеллекта (AI), содержащий этапы, на которых: a) инициализируют одну или более моделей машинного обучения (ML) на сервере; b) распространяют одну или более моделей ML среди одного или более пользовательских устройств (UE), соединенных с сервером посредством сети связи; c) накапливают данные, формируемые пользователем посредством пользовательского ввода, на каждом из одного или более UE в течение периода накопления данных; d) передают обучающие данные с сервера на одно или более UE; e) осуществляют обучение модели ML на каждом из одного или более UE на основании упомянутых собранных данных и упомянутых обучающих данных до выполнения критерия прекращения обучения; f) получают на сервере обученные модели ML от упомянутых одного или более UE; g) обновляют на сервере модель ML путем агрегации обученных моделей ML, полученных от одного или более пользовательских устройств; h) передают обновленные модели ML в одно или более UE; и i) повторяют этапы c) -h) один или более раз до получения модели ML, соответствующей одному или более критериям качества модели ML. 2. Способ по п. 1, дополнительно содержащий этапы, на которых: идентифицируют группу персонализации для пользователя каждого из одного или более UE на основании данных, формируемых пользователем, собранных на упомянутом каждом из одного или более UE; группируют на сервере модели ML, полученные от упомянутых одного или более UE, по группам персонализации; и передают обновленные модели ML, сгруппированные по группам персонализации, в UE, входящие в соответствующую группу персонализации. 3. Способ по п. 1, в котором модель ML выполнена с возможностью предсказания слов и словосочетаний при вводе пользователем текстового сообщения на UE, при этом формируемые пользователем данные представляют собой слова и словосочетания, вводимые пользователем. 4. Способ по п. 1, в котором модель ML выполнена с возможностью распознавания предметов на изображениях, получаемых с одной или более камер UE, при этом формируемые пользователем данные представляют собой изображения с одной или более камер UE и/или метки, присваиваемые пользователем предметам, присутствующим на изображениях. 5. Способ по п. 1, в котором модель ML выполнена с возможностью распознавания рукописного ввода, принимаемого от пользователя посредством сенсорного экрана UE и/или сенсорной панели UE, при этом формируемые пользователем данные представляют собой упомянутый рукописный ввод и/или выбор пользователем предлагаемых моделью ML вариантов символов и/или слов, основанных на рукописном вводе от пользователя. 6. Способ по п. 1, в котором модель ML выполнена с возможностью распознавания голосового ввода, принимаемого от пользователя посредством одного или более микрофона UE, при этом формируемые пользователем данные представляют собой упомянутый голосовой ввод и/или выбор пользователем предлагаемых моделью ML вариантов слов и/или словосочетаний, основанных на голосовом вводе от пользователя. 7. Способ по п. 1, в котором модель ML выполнена с возможностью распознавания одной или более характеристик окружения UE и/или одного или более действий пользователя, при этом одна или более характеристик окружения UE представляют собой одно или более из времени, даты, дня недели, освещенности, температуры, географического местоположения, пространственного положения UE, при этом формируемые пользователем данные представляют собой пользовательский ввод в одно или более программных приложений на UE. 8. Способ по п. 1, в котором обучающие данные включают в себя порцию общедоступных данных из исходной выборки. 9. Способ по п. 1, в котором критерием прекращения обучения является достижение сходимости моделей ML среди одного или более UE. 10. Способ по п. 1, в котором критерием прекращения обучения является достижение моделью ML заданного значения характеристики качества модели ML. 11. Способ по п. 1, в котором критерием прекращения обучения является достижение заданного количества периодов обучения. 12. Система распределенного обучения модели машинного обучения (ML) искусственного интеллекта (AI), содержащая: сервер и одно или более пользовательских устройств (UE), соединенных с сервером посредством сети связи; при этом сервер выполнен с возможностью: инициализации одной или более моделей машинного обучения (ML); распространения одной или более моделей ML среди одного или более пользовательских устройств (UE); передачи обучающих данных на одно или более UE; получения обученных моделей ML от одного или более UE; обновления модели ML путем агрегации обученных моделей ML, полученных от одного или более UE; передачи обновленных моделей ML в одно или более UE; и при этом одно или более UE выполнены с возможностью: накопления данных, формируемых пользователем посредством пользовательского ввода, в течение периода накопления данных; приема обучающих данных от сервера; обучения модели ML на основании упомянутых собранных данных и упомянутых обучающих данных до выполнения критерия прекращения обучения. 13. Машиночитаемый носитель, на котором сохранена компьютерная программа, которая при выполнении одним или более процессорами реализует способ по любому из пп. 1-12.
- METHOD AND SYSTEM FOR CONTACT TRACING USING A SOFTWARE DEVELOPMENT KIT (SDK) INTEGRATED INTO CLIENT DEVICES
- МПК G06Q30/02
- Документ WO 2021252880 A1 2021.12.16
- Заявитель AMBEENT INC.
- Автор ERGEN, Mustafa
The SDK further analyses the recorded past and current signal data/measurements of the one or more WiFi access points using an AI module to derive mobility patterns of a user of the client device. The AI module of the SDK then identifies other client devices that the client device may have encountered based on analyzing the mobility' paterns of the user of the client device and the recorded past and current signal data/measurements of the one or more Wi-Fi access points. For instance, the SDK identifies a total number of client devices connected to the one or more Wi-Fi access points, a number of other client devices the one or more Wi-Fi access points received signals from, MAC addresses of the connected client devices and the other client devices, and how long each client device stayed in close proximity? to the one or more Wi-Fi access points.
- INFORMATION REPORTING METHOD, APPARATUS AND DEVICE, AND STORAGE MEDIUM
- МПК H04W72/04
- Документ WO 2021142609 A1 2021.07.22
- Заявитель GUANGDONG OPPO MOBILE TELECOMMUNICATIONS CORP., LTD.
- Автор SHEN, Jia
... 信息上报方法、装置、设备和存储介质 技术领域 本申请涉及AI/ML和通信领域,特别是涉及一种信息上报方法、装置、设备和存储介质。 背景技术 人工智能(Artifical Intelligence,简称AI)与机器学习(Machine Learning,简称ML)正在移动通信终端中承担越来越多的重要任务,例如,拍照、图像识别、视频通话、AR/VR、游戏等都可能涉及到AI/ML业务,相应的,预计AI/ML业务在第五代移动通信技术(5th generation mobile networks,简称5G)、第六代移动通信技术(6th generation mobile networks,简称6G)网络上的传输,将成为未来的一种重要业务。 在智能手机、智能汽车、无人机、机器人等5G、6G移动终端中应用AI/ML业务会存在各种各样的场景,例如,移动终端与网络设备合作完成AI/ML业务的“AI/ML操作划分”场景,网络设备向移动终端下发所涉及的AI/ML模型的“AI/ML模型分发”场景,网络设备和移动终端训练AI/ML模型的“AI/ML模型训练场景”,等等。在不同的场景下,移动终端能够分配给AI/ML业务的芯片处理资源、存储资源等,也会随着场景和时间的变化而变化。 发明内容 基于此,有必要提供一种信息上报方法、装置、设备和存储介质。 第一方面,本发明的实施例提供一种信息上报方法,所述方法包括: 终端向网络设备发送人工智能AI/机器学习ML能力信息;所述AI/ML能力信息指示所述终端用于处理AI/ML业务的资源信息。 在一个实施例中,所述方法还包括: 所述终端接收所述网络设备发送的AI/ML任务配置信息;所述AI/ML任务配置信息用于指示所述网络设备根据所述AI/ML能力信息为所述终端分配的AI/ML任务配置。 第二方面,本发明的实施例提供一种信息上报方法,所述方法包括: 网络设备接收终端发送的AI/ML能力信息;所述AI/ML能力信息指示所述终端用于处理AI/ML业务的资源信息。 在一个实施例中,所述方法还包括: 所述终端向所述网络设备发送所述AI/ML训练任务的训练结果。 在一个实施例中,所述方法还包括: 所述网络设备向所述终端发送AI/ML任务配置信息;所述AI/ML任务配置信息用于指示所述网络设备根据所述AI/ML能力信息为所述终端分配的AI/ML任务配置。 ...
- IMPROVING RANDOM ACCESS BASED ON ARTIFICIAL INTELLIGENCE / MACHINE LEARNING (AI/ML)
- МПК H04W12/60
- Документ WO 2021215995 A9 2021.10.28
- Заявитель TELEFONAKTIEBOLAGET LM ERICSSON (PUBL)
- Автор PARICHEHREHTEROUJENI, Ali
The method of any of embodiments E1-E4, wherein: the method is performed by the particular UE; and obtaining the AI/ML model comprises receiving the AI/ML model from a network node in the wireless network. E12. The method of embodiment Ell, further comprising performing a random access to the cell based on the determined values. E13. The method of embodiment E12, further comprising: based on the random access being unsuccessful, determining that the AI/ML model needs to be retrained; requesting, from the network node, a further training dataset for retraining the model; and retraining the AI/ML mode based on the further training dataset and one or more measurements made by the particular UE. E14.
- IMPROVING RANDOM ACCESS BASED ON ARTIFICIAL INTELLIGENCE / MACHINE LEARNING (AI/ML)
- МПК H04W12/60
- Документ WO 2021215995 A1 2021.10.28
- Заявитель TELEFONAKTIEBOLAGET LM ERICSSON (PUBL)
- Автор PARICHEHREHTEROUJENI, Ali
The method of any of embodiments E1-E4, wherein: the method is performed by the particular UE; and obtaining the AI/ML model comprises receiving the AI/ML model from a network node in the wireless network. E12. The method of embodiment Ell, further comprising performing a random access to the cell based on the determined values. E13. The method of embodiment E12, further comprising: based on the random access being unsuccessful, determining that the AI/ML model needs to be retrained; requesting, from the network node, a further training dataset for retraining the model; and retraining the AI/ML mode based on the further training dataset and one or more measurements made by the particular UE. E14.
- РАСПРЕДЕЛЁННОЕ ОБУЧЕНИЕ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ ПЕРСОНАЛИЗАЦИИ
- МПК G09B9/00
- Документ RU 2702980 C1 2019.10.14
- Автор КУДИНОВ Михаил Сергеевич (RU)
В соответствии с другим аспектом настоящего изобретения предложена система распределенного обучения модели машинного обучения (ML) искусственного интеллекта (AI), содержащая: сервер; и одно или более пользовательских устройств (UE), соединенных с сервером посредством сети связи; при этом сервер выполнен с возможностью: инициализации одной или более моделей машинного обучения (ML); распространения одной или более моделей ML среди одного или более пользовательских устройств (UE); передачи обучающих данных на одно или более UE; получения обученных моделей ML от одного или более UE; обновления модели ML путем усреднения обученных моделей ML, полученных от одного или более UE; передачи обновленных моделей ML в одно или более UE; и при этом одно или более UE выполнены с возможностью: накопления данных, формируемых пользователем посредством пользовательского ввода, в течение периода накопления данных; приема обучающих данных от сервера; обучения модели ML на основании упомянутых собранных данных ...
- ARTIFICIAL INTELLIGENCE OPERATION PROCESSING METHOD AND APPARATUS, SYSTEM, TERMINAL, AND NETWORK DEVICE
- МПК H04L29/08
- Документ WO 2021142637 A1 2021.07.22
- Заявитель GUANGDONG OPPO MOBILE TELECOMMUNI-CATIONS CORP., LTD.
- Автор SHEN, Jia
... 图9是根据本发明优选实施方式所提供的终端根据网络设备的指示动态调整AI/ML操作划分模式的示意图,如图9所示,网络设备动态调度网络设备与终端执行AI/ML任务的AI/ML操作划分模式。终端根据网络设备的指示信息,确定终端负责执行的AI/ML操作,同时网络设备执行其他的AI/ML操作,形成一种AI/ML操作划分模式。网络设备也可以通过新的指示信息,调整AI/ML操作划分模式,并确定终端负责执行的AI/ML操作,同时网络设备改为执行剩余的AI/ML操作,进入另一种AI/ML 操作划分模式。 优选实施方式2:通过AI/ML模型切换实现AI/ML操作的重新划分 图10是根据本发明优选实施方式所提供的网络设备根据终端AI/ML算力变化,指示终端切换AI/ML模型的示意图,如图10所示,假设在第一时段终端可用于此项AI/ML任务的AI/ML算力(即上述所指的计算能力)较高,可以运行相对复杂的AI/ML模型1,则网络设备可以运行与AI/ML模型1相匹配的网络设备AI/ML模型,这两个模型构成AI/ML操作划分模式1。在时间点T1,终端能够分配给此项AI/ML任务的AI/ML算力降低,无法继续运行AI/ML模型1,但可以运行复杂度较低的AI/ML模型2。因此网络设备可通过指示信息指示终端切换到AI/ML模型2,同时网络设备也切换到与AI/ML模型2相匹配的网络设备AI/ML模型,形成新的AI/ML操作划分模式2。 上述网络设备指示的终端AI/ML模型切换机制,可以实现与终端AI/ML计算资源相适配的AI/ML操作划分模式,从而在保证终端AI/ML操作的可靠性的同时,尽量充分利用终端和网络设备的AI/ML计算能力。 图11是根据本发明优选实施方式所提供的网络设备根据可实现通信速率的变化,指示终端切换AI/ML模型的示意图,如图11所示,假设在第一时段终端和网络设备的无线通信信道可实现的数据率较低,只能运行相对复杂、但对通信速率要求较低的AI/ML模型1,网络设备则运行与AI/ML模型1相匹配的网络设备AI/ML模型,这两个模型构成AI/ML操作划分模式1。在时间点T1,终端和网络设备之间能实现的数据率提高,终端可以转而运行复杂度较低、但对通信速率要求较高的AI/ML模型2。 ...
- SYSTEM AND METHODS FOR AMALGAMATION OF ARTIFICIAL INTELLIGENCE (AI) AND MACHINE LEARNING (ML) IN TEST CREATION, EXECUTION, AND PREDICTION
- МПК G06F11/36
- Документ US 20200341888 A1 2020.10.29
- Заявитель HEWLETT PACKARD ENTERPRISE DEVELOPMENT LP
- Автор Pavan Sridhar
The AI/ML analyzer is designed to leverage the robust capabilities of AI/ML to provide an analysis of software tests used during automated software testing, so as to improve the overall performance and efficiency of the automation. For example, the AI/ML test analyzer can apply various AI/ML approaches during its analysis of a software test suite, which includes a predetermined sequence of software test that may have been selected by a software engineer. The AI/ML analyzer can use AI/ML techniques in conjunction with collected software test log data in order to predict an optimal combination of software tests for the software suite, which may include newly added software tests, and/or a rearranged sequence of software tests as compared to the human-generated software test suite. Even further, the AI/ML analyzer has adaptability with respect to its integration into the software development lifecycle.
- A HYBRID COGNITIVE SYSTEM FOR AI/ML DATA PRIVACY
- МПК G06Q10/06
- Документ EP 3803731 A1 2021.04.14
- Заявитель Cisco Technology, Inc.
- Автор GRIFFIN, Keith
- METHOD AND SYSTEM FOR CONTACT TRACING USING A SOFTWARE DEVELOPMENT KIT (SDK) INTEGRATED INTO CLIENT DEVICES
- МПК G16H40/67
- Документ US 20210391072 A1 2021.12.16
- Заявитель Ambeent Wireless
- Автор Mustafa Ergen
Each client device of plurality of client devices 102A-102N further includes a Software Development Kit (SDK) 106 which utilizes an AI-based technology to perform contact tracing by tracking human mobility patterns and contact points, making use of Wi-Fi signals sent/received via SDK 106. SDK 106 can be integrated into any client device application such as, but not limited to, a mobile application. Using SDK 106, a client device 102A of plurality of client devices 102A-102N tracks and records signals/measurements of one or more Wi-Fi access points of plurality of Wi-Fi access points 104A-104N in vicinity of the client device. SDK 106 maintains a list of Wi-Fi access points encountered by client device 102A in a local memory of client device 102A. SDK 106 uses the AI-based technology to analyze the recorded signals/measurements to identify a list of other client devices that client device 102A encountered, for contact tracing.
- SYSTEM AND METHODS FOR AMALGAMATION OF ARTIFICIAL INTELLIGENCE (AI) AND MACHINE LEARNING (ML) IN TEST CREATION, EXECUTION, AND PREDICTION
- МПК G06F11/00
- Документ US 0011221942 B2 2022.01.11
- Заявитель HEWLETT PACKARD ENTERPRISE DEVELOPMENT LP
- Автор Pavan Sridhar
The AI/ML analyzer is designed to leverage the robust capabilities of AI/ML to provide an analysis of software tests used during automated software testing, so as to improve the overall performance and efficiency of the automation. For example, the AI/ML test analyzer can apply various AI/ML approaches during its analysis of a software test suite, which includes a predetermined sequence of software test that may have been selected by a software engineer. The AI/ML analyzer can use AI/ML techniques in conjunction with collected software test log data in order to predict an optimal combination of software tests for the software suite, which may include newly added software tests, and/or a rearranged sequence of software tests as compared to the human-generated software test suite. Even further, the AI/ML analyzer has adaptability with respect to its integration into the software development lifecycle.
- PERSONALIZED TAILORED AIR INTERFACE
- МПК H04W8/24
- Документ WO 2021098159 A1 2021.05.27
- Заявитель HUAWEI TECHNOLOGIES CO., LTD.
- Автор MA, Jianglei
The AI/ML capability type may identify whether the UE supports AI/ML optimization of one or more components of the air interface of the device. For example, the AI/ML capability type may be one of a plurality of AI/ML capability types, where each AI/ML capability type corresponds to support for a different level of AI/ML capability. For example, the plurality of AI/ML capability types may include an AI/ML capability type that indicates the UE supports deep learning. As another example, the plurality of AI/ML capability types may include different types that indicate different combinations of air interface components that are optimizable by AI/ML.
- AI/ML BASED DRILLING AND PRODUCTION PLATFORM
- МПК E21B44/00
- Документ WO 2021040764 A1 2021.03.04
- Заявитель LANDMARK GRAPHICS CORPORATION
- Автор RANGARAJAN, Keshava, Prasad
The system 100 can be used to generate optimal drilling paths and optimal production control variables based on relevant data models, various AI algorithms, and ML algorithms. The drilling patterns can be generated for consumer consumption to assist in and improved performance of drilling and production operations and/or the automation and improved performance, i.e. control and accuracy, of drilling and production equipment. [0019] The predictive engine 24a can comprise a drill path and production control pattern recognition component 130 and an ML engine 140. The pattern recognition component 130 can comprise an AI engine 132, a simulator 134, and an optimization engine 136.
- FUNCTIONAL ARCHITECTURE AND INTERFACE FOR NON-REAL-TIME RAN INTELLIGENT CONTROLLER
- МПК H04L12/24
- Документ WO 2021215847 A1 2021.10.28
- Заявитель SAMSUNG ELECTRONICS CO., LTD.
- Автор LO, Caleb K.
An external AI/ML server (in the case of the first option) may possess the following capabilities in part or entirety to support a generic non-RT RIC 402 as exemplified in FIG. 4A: ● Data preparation ● Including data selection, fusion, cleaning, etc. ● AI/ML modeling ● Including feature extraction, model selection, etc. ● AI/ML model training ● AI/ML model verification ● AI/ML model inference ● AI/ML model feedback ● AI/ML model training feedback for A1 policies ● AI/ML model training feedback for near-RT RIC parameters ● AI/ML model training feedback for RAN parameters ● Assisting non-RT RIC with AI/ML model maintenance ● Including metadata with AI/ML model feedback ● Including metadata with AI/ML model training feedback The interface between non-RT RIC 402 and AI/ML server may convey in part of or an entirety of: ● SMO data from non-RT RIC to AI/ML server ● the following from AI/ML server to non-RT RIC: ○ Trained AI/ML models ○ Training results for A1 policies ○ Training results for RAN ...
- OPTIMIZING AI/ML MODEL TRAINING FOR INDIVIDUAL AUTONOMOUS AGENTS
- МПК G06N20/00
- Документ US 20210117864 A1 2021.04.22
- Заявитель John Charles Weast
- Автор John Charles Weast
At operation 208, one or more trained AI/ML models are deployed (e.g., within the one or more autonomous vehicle(s) 102). At operation 210, the one or more AI/ML models are enabled or disabled based on a location of the vehicle to enforce restrictions and/or implement rights of use pertaining to the AI/ML models when going inside or outside of designated regions. Thus, for example, a baseline AI/ML model having been trained with no regulated data or trained with reduced regulated data may be enabled within an autonomous vehicle when the autonomous vehicle enters a jurisdiction as a replacement for a different AI/ML model (having been trained with a greater amount regulated data) (e.g., to avoid an unfavorable DST impact). In example embodiments, the replacement of the model may be performed on the fly (e.g., as the vehicle moves from one jurisdiction to another). FIG. 3 is a block diagram of a system 300 for a base station.
- DYNAMIC ARTIFICIAL INTELLIGENCE / MACHINE LEARNING MODEL UPDATE, OR RETRAIN AND UPDATE, IN DIGITAL PROCESSES AT RUNTIME
- МПК G06F8/65
- Документ EP 3839725 A1 2021.06.23
- Заявитель UiPath, Inc.
- Автор OROS, Andrei Robert
When a notification 652 is received that a new AI/ML model or a retrained version of the current AI/ML model is available, FSM 600 enters an update state 650. FSM execution status 1200 during AI/ML model update in FIG. 12 . In update state 650, the AI/ML model file is changed to the new AI/ML model file. This essentially replaces the production AI/ML model with the updated AI/ML model. FSM 600 then enters a transition 654 to reinitialize with the new AI/ML model, and FSM 600 returns to initialization state 610, where the new AI/ML model is initialized. FIG. 13 is a screenshot illustrating a sequence 1300 for updating the AI/ML model, according to an embodiment of the present invention. A write line activity 1310 informs the user that the AI/ML model is being updated. A retraining checking activity 1320 checks whether retraining of the AI/ML model is currently occurring. If so, sequence 1300 delays the AI/ML model update until retraining is completed.
- SYSTEM TO MITIGATE AGAINST ADVERSARIAL SAMPLES FOR ML AND AI MODELS
- МПК G06K9/62
- Документ US 20200394466 A1 2020.12.17
- Заявитель Baidu USA LLC
- Автор Yunhan JIA
More particularly, embodiments of the invention relate to a system to mitigate against adversarial samples for machine learning (ML) and artificial intelligence (AI) models. BACKGROUND ML and/or AI models can be provided through cloud APIs by cloud providers, which can be used by applications to censor/filter content, and classify/detect malwares/threats. However, adversaries can send continuous queries to probe a “blind spot” of the ML or AI models to generate “adversarial samples” to fool the ML or AI models. Manual inspections of the filtered content and detections can be performed by humans to identify adversarial samples. But this approach is time consuming and not scalable. BRIEF DESCRIPTION OF THE DRAWINGS Embodiments of the invention are illustrated by way of example and not limitation in the figures of the accompanying drawings in which like references indicate similar elements. FIG. 1 is a block diagram illustrating a networked system according to one embodiment.
- DATA PROCESSING DEVICE AND METHOD FOR REDUCING THE COMPLEXITY OF A SECTION NETWORK
- МПК G07B15/06
- Документ EP 3300030 A1 2018.03.28
- Заявитель Toll Collect GmbH
- Автор Bartz, Gerald
Im Falle der beiden folgenden Ausführungsbeispiele sind sämtliche bestimmte Mehrfachabschnittssequenzen Ml vollständige Mehrfachabschnittssequenzen Ml, die dadurch gekennzeichnet sind, dass jede Mehrfachabschnittssequenz Ml mit der Zufahrt auf einen ersten Streckenabschnitt Ai aus dem zweiten Netz beginnt und mit der Abfahrt von einem zweiten Streckenabschnitt Aj, j ≠ i, in das zweite Netz endet. Derartige vollständige Mehrfachabschnittssequenzen Ml sind in dieser Hinsicht inklusionsmaximal, als dass ihnen kein weiterer Streckenabschnitt Ai der jeweiligen Fahrspur Fk zur Bildung einer längeren Mehrfachabschnittsequenz mehr hinzugefügt werden kann.
- STABILE, KONZENTRIERTE RADIONUKLIDKOMPLEXLÖSUNGEN
- МПК A61K51/08
- Документ DE 202018006567 U1 2021.04.01
- Заявитель Advanced Accelerator Applications SA
... (ai) und (aii) vorliegt und Ascorbinsäure nach der Komplexbildung der Komponenten (ai) und (aii) zugefügt wird und wobei es sich bei dem einzigen Stabilisator, der während der Komplexbildung der Komponenten (ai) und (aii) vorliegt, um Gentisinsäure handelt, die während der Komplexbildung in einer Konzentration von 20 bis 40 mg/ml, vorzugsweise von 25 bis 35 mg/ml, vorliegt.
- SYSTEM TO MITIGATE AGAINST ADVERSARIAL SAMPLES FOR ML AND AI MODELS
- МПК G06K9/00
- Документ US 0011216699 B2 2022.01.04
- Заявитель Baidu USA LLC
- Автор Yunhan Jia
More particularly, embodiments of the invention relate to a system to mitigate against adversarial samples for machine learning (ML) and artificial intelligence (AI) models. BACKGROUND ML and/or AI models can be provided through cloud APIs by cloud providers, which can be used by applications to censor/filter content, and classify/detect malwares/threats. However, adversaries can send continuous queries to probe a “blind spot” of the ML or AI models to generate “adversarial samples” to fool the ML or AI models. Manual inspections of the filtered content and detections can be performed by humans to identify adversarial samples. But this approach is time consuming and not scalable. BRIEF DESCRIPTION OF THE DRAWINGS Embodiments of the invention are illustrated by way of example and not limitation in the figures of the accompanying drawings in which like references indicate similar elements. FIG. 1 is a block diagram illustrating a networked system according to one embodiment.
- PROCEDEU DE COMBATERE BIOLOGICĂ A CĂPUŞELOR FITOFAGE
- МПК A01N63/00
- Документ MD 0000003069 G2 2007.01.31
- Заявитель ИНСТИТУТ ЗООЛОГИИ АКАДЕМИИ НАУК РЕСПУБЛИКИ МОЛДОВА, MD
- Автор ТОДЕРАШ Ион, MD
Din microsporidiile extrase se pregăteşte suspensia cu apă distilată în concentraţie de 1000 spori la 1 ml de apă. Eficacitatea procedeului a fost verificată pe diverse specii de căpuşe fitofage, dăunători ai culturilor agricole economic importante. Exemplul 1 Estimarea eficacităţii procedeului de combatere a căpuşei Eriophyes vitis - dăunător al viţei de vie. Preliminar, cu 2 săptămâni până la prelucrarea cu suspensie de microsporidii s-au populat câte 500 căpuşe pe 20 tufe de viţă de vie în vârstă de 2 ani, iniţial testate la absenţa căpuşelor fitofage. Ulterior 10 arbuşti au fost trataţi cu suspensie de microsporidii N. slovaka , câte 50 ml pentru fiecare tufă, prin pulverizare, astfel, ca toate frunzele plantei să fie umectate cu soluţie. Alte 10 tufe nu au fost tratate cu suspensie - varianta martor. Efectul procedeului este evaluat vizual, monitorizând nivelul vătămării frunzelor viţei de vie de căpuşa E. vitis timp de 60 zile. Rezultatele, sunt prezentate în tabel.
- SYMBOLS INCORPORATION SCHEME FOR DFT-S-OFDM
- МПК H04L27/26
- Документ EP 3599748 B1 2020.12.16
- Автор CIOCHINA, Cristina
The value ρni+mL of the symbol Xni+mL is ej2πk(ni+mL)/MAi. Therefore, Xni+mL is one of the symbols of the block of symbols that conveys the symbol Ai. At the receiver side the symbol Ai can easily be retrieved from the samples of the symbols Xni+mL, with 0 ≤ m < K. The symbol Ai is for example a modulation symbol like a QPSK modulation symbol or a symbol from a given sequence such as a CAZAC sequence or a symbol from a predefined sequence with controlled PAPR for example. The symbols Xni+mL are the symbol Ai with phase shift. The values, to which the symbols Xni+mL are set to, can be for examples phase shifted symbols of a digital modulation scheme, or phase shifted symbols taken from a CAZAC sequence or from another predefined sequence with controlled PAPR. Samples of the symbol Ai are the same than the samples of the symbols Xni+mL, with 0 ≤ m < K. The index k and the integer K define the comb.
- PERSONALIZED TAILORED AIR INTERFACE
- МПК H04L12/24
- Документ US 20210160149 A1 2021.05.27
- Заявитель JIANGLEI MA
- Автор JIANGLEI MA
The AI/ML capability type may identify whether the UE supports AI/ML optimization of one or more components of the air interface of the device. For example, the AI/ML capability type may be one of a plurality of AI/ML capability types, where each AI/ML capability type corresponds to support for a different level of AI/ML capability. For example, the plurality of AI/ML capability types may include an AI/ML capability type that indicates the UE supports deep learning. As another example, the plurality of AI/ML capability types may include different types that indicate different combinations of air interface components that are optimizable by AI/ML.
- ANTIKÖRPER-INDEX KONTROLLE
- МПК G01N33/53
- Документ DE 202005020150 U1 2006.06.22
- Заявитель Genzyme Virotech GmbH, 65428 Rüsselsheim, DE
Verwendungszweck [0015] Das Antikörper-Index-Kontrollenpaar dient im Rahmen der infektionsserologischen Liquordiagnostikzur Bestimmung von Richtigkeit und Präzision des Antikörperindex und ermöglicht damit eine umfassendeQualitätskontrolle in der täglichen Liquor-Routinediagnostik. [0016] Die Sollwerte der Liquor/Serum-Kontrollenpaare sind so gewählt, daß sowohl Antikörperindizesim Normalbereich (AI < 1,5) als auch Antikörperindizes im pathologisch erhöhten Bereich (AI≥ 1,5) kontrolliert werden können. Packungsinhalt 1. Liquor/Serum-Kontrollenpaar für den Normalbereich (AI<1,5) Liquor, 1 ml, (Liquormatrix äquivalentes Material aus hochverdünntem Humanserum mit Zusatz vonProteinstabilisatoren und Konservierungsmittel, gebrauchsfertig) Serum, 1 ml, Humanserum mit Proteinstabilisatoren und Konservierungsmittel, gebrauchsfertig2.
- SYSTEMS AND METHODS FOR SAFEGUARDING ARTIFICIAL INTELLIGENCE-BASED NETWORK CONTROL AND PROACTIVE NETWORK OPERATIONS
- МПК H04L12/24
- Документ WO 2020163559 A1 2020.08.13
- Заявитель CIENA CORPORATION
- Автор ONG, Lyndon, Y.
That is, human feedback for the safeguard can be used to improve the accuracy of ML models. Risks associated with AI-driven systems [00100] While these types of ML have led to breakthroughs in AI capability such as unbeatable (by humans) chess, Atari, and Go-playing systems, or image recognition systems, there are concerns with using them in real-world deployments.
- DISTRIBUTED TRAINING OF MACHINE LEARNING MODELS FOR PERSONALIZATION
- МПК G06N20/00
- Документ WO 2020122669 A1 2020.06.18
- Заявитель SAMSUNG ELECTRONICS CO., LTD.
- Автор KUDINOV, Mikhail Sergeevich
For this purpose, an additional unit may be provided at the server side for generating new ML model architectures and hyperparameters for these models. Any AI system may also be extended by including additional functions, if necessary, which allow testing new ML models on user generated data. The present invention is implemented in a standard wireless communication network architecture and includes hardware and/or software means at the server side and hardware and/or software means at the user equipment side.
- DYNAMIC ARTIFICIAL INTELLIGENCE / MACHINE LEARNING MODEL UPDATE, OR RETRAIN AND UPDATE, IN DIGITAL PROCESSES AT RUNTIME
- МПК G06K9/62
- Документ US 20200134374 A1 2020.04.30
- Заявитель UiPath, Inc.
- Автор Andrei Robert Oros
The instructions are configured to cause the at least one processor to listen for a retraining request for an AI/ML model. When the retraining request is received to retrain the AI/ML model, the instructions are configured to cause the at least one processor to initiate retraining of the AI/ML model. The retraining of the AI/ML model occurs during runtime of the digital process. In still another embodiment, a computer-implemented method for dynamic update, or retraining and update, of an AI/ML model includes listening for an update request for the AI/ML model, by an RPA digital process executing on a computing system. When the update request is received to update the AI/ML model, the computer-implemented method includes reinitializing or re-instantiating the RPA digital process to call an updated version of the AI/ML model and listening for another update request, by the RPA digital process executing on the computing system.
- PROACTIVE USER INTERFACE INCLUDING EMOTIONAL AGENT
- МПК G06F9/44
- Документ EP 1522920 B1 2013.06.05
- Автор Lee, Jong-Goo c/o Samsung Elect. Co., Ltd.
The TeachingApp 306 is only one non-limiting example of a generic application which may be implemented over the AI framework layer. The AI framework layer itself contains one or more components which enable the user interface to behave in a proactive manner. The framework can include a DeviceWorldMapper 308, for determining the state of the computational device and also that of the virtual world, as well as the relationship between the two states. The DeviceWorldMapper 308 receives input, for example from various events from an EventHandler 310, in order to determine the state of the virtual world and that of the device. The DeviceWorldMapper 308 also communicate with an AI/ML (machine learning) module 312 for analyzing input data.
- COMMUNICATION METHOD AND DEVICE, AND ELECTRONIC DEVICE AND COMPUTER-READABLE STORAGE MEDIUM
- МПК H04W28/18
- Документ WO 2021253232 A1 2021.12.23
- Заявитель BEIJING XIAOMI MOBILE SOFTWARE CO., LTD
- Автор LI, Yanhua
... 作为一个示例,基于第一信息确定是否发起AI/ML操作类型的业务可以包括以下至少一项:响应于至少一项网络节点能力指示信息中的至少一者与相对应的门限比较的结果,确定是否发起AI/ML操作类型的业务;响应于至少一项终端能力信息中的至少一者与相对应的门限比较的结果,确定是否发起AI/ML操作类型的业务;响应于接入策略信息中的至少一者是否被满足的判断结果,确定能够发起AI/ML操作类型的业务。 与上文相似地,网络节点可以针对不同的AI/ML操作类型的业务发送不同的第一信息,终端可以基于网络节点发送的信息来进行判决,以确定是否发起AI/ML操作类型的业务。例如,当网络节点向终端发送第一信息中的多项信息以及指定第一信息中的有效信息的指示规则时,终端直接可以根据多项信息中的指示规则所指定的有效信息来判决是否发起AI/ML操作类型的业务。例如,当指示规则被预先写入到终端或连接到终端的设备时,网络节点可以仅发送第一信息中的多项信息,终端在接收到多项信息时,可以在本地获取指示规则,然后根据指示规则确定多项信息中的哪些信息是有效的,并且利用有效的信息来判决是否发起AI/ML操作类型的业务。 换言之,终端可以从第一信息中确定至少一项有效信息,并且确定所述至少一项有效信息是否被同时满足,从而判决是否发起AI/ML操作类型的业务。 假设与网络节点能力相关的信息中的计算能力指示信息及其门限是有效的,则终端进行判决的步骤可以包括:响应于比较结果为:网络节点的计算能力(网络节点的内存、CPU、存储空间中的至少一者的占用情况)低于或等于相应的门限(即,计算能力指示信息满足相应的门限),终端确定可以发送发起AI/ML操作类型的业务。 假设与网络节点能力相关的信息中的无线资源能力指示信息及其门限是有效的,则终端进行判决的步骤可以包括:响应于比较结果为:网络节点提供的带宽高于或等于相应的门限(即,无线资源能力指示信息满足门限),终端确定可以发送发起AI/ML操作类型的业务,和/或响应于终端检测到信号强度或信号质量(例如,RSRP(参考信号接收功率,Reference Signal Receiving Power))高于或等于相应的门限(即,无线资源能力指示信息满足门限),终端确定可以发起AI/ML操作类型的业务。 ...
- FUNCTIONAL ARCHITECTURE AND INTERFACE FOR NON-REAL-TIME RAN INTELLIGENT CONTROLLER
- МПК H04W28/02
- Документ US 20210337420 A1 2021.10.28
- Заявитель Samsung Electronics Co., Ltd.
- Автор Caleb K. Lo
... AI/ML model training AI/ML model verification AI/ML model inference AI/ML model feedback AI/ML model training feedback for A1 policies AI/ML model training feedback for near-RT RIC parameters AI/ML model training feedback for RAN parameters Assisting non-RT RIC with AI/ML, model maintenance Including metadata with AI/ML model feedback Including metadata with AI/ML model training feedback The interface between non-RT RIC 402 and AI/ML server may convey in part of or an entirety of: SMO data from non-RT RIC to AI/ML server the following from AI/ML server to non-RT RIC: Trained AI/ML models Training results for A1 policies Training results for RAN/near-RT RIC parameters In addition, the interface between non-RT RIC 402 and AI/ML server may support the following functionalities as well as necessary information exchange: Support AI/ML lifecycle management in AI/ML server Monitoring and analytics may be handled in SMO Support transfer of mediated SMO data to AI/ML server to enable data prep Data ...
- ARTIFICIAL INTELLIGENCE-BASED ROLEPLAYING EXPERIENCES BASED ON USER-SELECTED SCENARIOS
- МПК G06F17/27
- Документ US 20210081498 A1 2021.03.18
- Заявитель Disney Enterprises, Inc.
- Автор Michael P. GOSLIN
DETAILED DESCRIPTION Embodiments of the present disclosure provide AI systems that utilize machine learning to interact with users in a dynamic and immersive manner. In an embodiment, the AI system utilizes a collection of machine learning (ML) models, each trained on specified context or scope. In this way, each ML model can be narrowly-tailored, while the AI system retains broad applicability. In such an embodiment, the AI system determines the context of a given input, and generates responses using one or more ML models that correspond to that context. In one embodiment, the AI system can dynamically select ML models as the context of the interaction shifts, in order to continue to provide deep conversation. In some embodiments, the AI system acts as an intelligent character in a role-playing game. In one embodiment, the AI system infers the context of the conversation based on input as the user interacts with the character.
- NATRIURETIC PEPTIDES AND PLACENTAL-GROWTH FACTOR/SOLUBLE VEGF-RECEPTOR DISCRIMINATE CARDIAC DYSFUNCTION RELATED TO HEART DISEASE FROM A PLACENTA-ASSOCIATED CARDIAC DYSFUNCTION IN PREGNANT WOMAN
- МПК G01N33/68
- Документ EP 1903339 B1 2010.08.04
- Автор Hess, Georg, Prof. Dr.
Normal NT-proBNP values of pregnant women correspond to a plasma level of NT-proBNP of less than 125 pg/ml, particularly of less than 76 pg/ml, more particularly of less than 50 pg/ml. The elevation of NT-proBNP levels of preeclamptic pregnant women is associated with the severity of the disease. According to the present invention, increased levels of NT-proBNP correspond to a plasma level of NT-proBNP of 125 pg/ml to 300 pg/ml, highly increased levels of NT-proBNP correspond to a plasma level of NT-proBNP of 300 pg/ml to more than 500 pg/ml indicating a cardiac dysfunction relating to a primary heart disease or to placenta-associated cardiac dysfunction. According to the present invention the term "a not decreased level of PIGf and / or a not increased level of sFlt-1 and / or the sFLt-1/PIGF ratio" refers to levels of control samples of a healthy reference colletive.
- ARTIFICIAL INTELLIGENCE-DRIVEN QUANTUM COMPUTING
- МПК G06N10/00
- Документ WO 2020113339 A1 2020.06.11
- Заявитель 1QB INFORMATION TECHNOLOGIES INC.
- Автор RONAGH, Pooya
The AI control unit may be configured to perform at least one artificial intelligence (AI) procedure to determine one or more tunable parameters for the computation. The AI control unit may be configured to direct the one or more tunable parameters to the non-classical computer. The AI procedure may comprise any AI procedure described herein. The AI procedure may comprise at least one machine learning (ML) procedure. The ML procedure may comprise any ML procedure described herein. The ML procedure may comprise at least one ML training procedure. The ML procedure may comprise at least one ML inference procedure. The AI procedure may comprise at least one reinforcement learning (RL) procedure. The RL procedure may comprise any RL procedure described herein. For instance, the AI procedure may comprise a training procedure described herein with respect to method 1400 of FIG. 14.
- SYSTEM OF A WEARABLE LASER DEVICE AND AN AI OR ML BASED PLATFORM WITH SMART VIRTUAL ASSISTANT FOR MONITORING AND TREATMENT OF PAIN INCLUDING PERIPHERAL NEUROPATHY
- МПК A61N5/06
- Документ US 20210260399 A1 2021.08.26
- Заявитель Abijith Kariguddaiah
- Автор Abijith Kariguddaiah
... /ML powered platform.
- USING ARTIFICIAL INTELLIGENCE TO SELECT AND CHAIN MODELS FOR ROBOTIC PROCESS AUTOMATION
- МПК G06N20/20
- Документ WO 2021076223 A1 2021.04.22
- Заявитель UIPATH, INC.
- Автор SINGH, Prabhdeep
For example, some embodiments of the present invention pertain to using AI to select and/or chain models for RPA. [0005] In an embodiment, a computer-implemented method for using AI to select and/or chain ML models for RPA includes executing, by a computing system, a model of models that analyzes performance of individual ML models and chains of ML models in an ML model pool to be called in a workflow of an RPA robot.
- SMALL CARBONATED BEVERAGE PACKAGING WITH ENHANCED SHELF LIFE PROPERTIES
- МПК B65D1/02
- Документ EP 3174803 B1 2020.12.16
- Автор CHIANG, Casper W.
As used herein, "weight distribution efficiency" or WDE of a container calculated according to "Method A" is defined according to the formula: WDE = A W ∑ i = 1 i = n a i w i × Ai wherein: ai is the area of the ith container section; wi is the weight of the ith container section; A is the total area of the container; Ai is the area fraction for section i W is the total weight of the container; and i is one of n total sections into which the container is divided, each section equally spanning i/n of the total container height measured from the bottom of the base to the bottom of the support ring. Typically, when using Method A of calculating WDE, n will be 4, 5, or 6, although any number of sections can be used. That is, for the purposes of calculating WDE, there typically will be 4, 5, or 6 sections that are sectioned as illustrated in Figure 7 .
- A HYBRID COGNITIVE SYSTEM FOR AI/ML DATA PRIVACY
- МПК G06Q10/06
- Документ WO 2019236849 A1 2019.12.12
- Заявитель CISCO TECHNOLOGY, INC.
- Автор GRIFFIN, Keith
A HYBRID COGNITIVE SYSTEM FOR AI/ML DATA PRIVACY RELATED APPLICATION DATA [0001] This application claims priority to U.S. application number 16/002,934, filed on June 7, 2018, the contents of which are hereby incorporated by reference in its entirety. TECHNICAL FIELD [0002] The present disclosure relates generally to protecting private data when training machine learning models, and more specifically pertains to a hybrid system for training and deploying machine learned models wherein private data is maintained in a private cloud. BACKGROUND [0003] Typically services that can determine the semantic meaning of text or speech consists of a set of cloud services that are accessed through a local client such as a voice, text, or video endpoint. These services can be, for example, live and/or recorded meeting transcriptions, cognitive artificial intelligence (AI) services, virtual assistants, etc. Cloud services are useful for many text or speech services.
- SAFEGUARDING ARTIFICIAL INTELLIGENCE-BASED NETWORK CONTROL
- МПК H04L12/24
- Документ US 20200259717 A1 2020.08.13
- Заявитель Ciena Corporation
- Автор Lyndon Y. Ong
The AI system 20 which can be one or more ML applications can utilize the data in the data lake 108 for automated control of the network 12, in conjunction with a policy engine 110. The safeguard module 102 is connected to the AI system 20, between the AI system 20 and the controller 22. Optionally, an operator 112 (human) can interface with the safeguard module 102. The controller 22, such as an SDN controller, is connected to the RA 104 for communication to the network elements 14. Advantageously, the AI-driven system 100 leverages accurate ML insights for 99.9% of situations but includes a deterministic safeguard module 102 to guarantee that ML accuracy remains bounded. In an example operation, the safeguard module 102 takes inputs from a single ML algorithm implemented by the AI system 20. Here, the safeguard module 102 can look at the statistical uncertainties reported by the ML algorithm itself to flag ambiguous insights.
- METHOD FOR ARCHIVING DOCUMENTS
- МПК G06F16/93
- Документ EP 3719670 A1 2020.10.07
- Заявитель Visma Consulting Oy
- Автор KUOSMANEN, Pekka
This method utilizes artificial intelligence (AI) and machine learning (ML) to convert the corpus of documents into a numerical term-document matrix. Supervised and unsupervised machine learning (ML) algorithms are applied on the mentioned numerical term-document matrix to analyze documents to classify documents, extract the hidden hierarchies of documents, summarizes each document, extract keywords from each document, discover similarities among documents, and extract relevant metadata of each document. ADVANTAGES OF THE INVENTION In the method according to the invention AI/ML-algorithms automatically recognize metadata of a document from provided external sources and add the metadata to the document to be archived. Therefore, manual mapping of metadata and using integration software are no longer needed. Another advantage is that the metadata can be extracted from the content of a document using Natural Language Processing methodology.
- COMPLEX HUMAN-COMPUTER INTERACTIONS
- МПК G06N20/00
- Документ US 20210406778 A1 2021.12.30
- Заявитель Bank of America Corporation
- Автор Ramakrishna R. Yannam
Step 502 shows providing a human chat responder's selected artificial intelligence (AI) based response (or partially AI-based response) to a chat initiator. It should be noted that, in certain embodiments, step 502 could also relate to a situation where the system is providing a human chat responder's response that is generated by the responder and does not depend solely, or even partially, on the AI response. Step 504 shows receiving the chat-initiator's response to the selected AI response. At 506, the diagram further shows integrating the chat initiator's response into an existing ML library to improve accuracy and efficiency of, and increase the stored information resident in, the ML library. It should be noted, and is generally known, that the more information stored in the ML library, the typically greater the possibility of a relevant and appropriate answer being returned.
- COMPLEX HUMAN-COMPUTER INTERACTIONS
- МПК H04L12/18
- Документ US 0011144846 B1 2021.10.12
- Заявитель Bank of America Corporation
- Автор Ramakrishna R. Yannam
Step 502 shows providing a human chat responder's selected artificial intelligence (AI) based response (or partially AI-based response) to a chat initiator. It should be noted that, in certain embodiments, step 502 could also relate to a situation where the system is providing a human chat responder's response that is generated by the responder and does not depend solely, or even partially, on the AI response. Step 504 shows receiving the chat-initiator's response to the selected AI response. At 506, the diagram further shows integrating the chat initiator's response into an existing ML library to improve accuracy and efficiency of, and increase the stored information resident in, the ML library. It should be noted, and is generally known, that the more information stored in the ML library, the typically greater the possibility of a relevant and appropriate answer being returned.
- AI/ML AND BLOCKCHAINED BASED AUTOMATED RESERVOIR MANAGEMENT PLATFORM
- МПК H04L9/06
- Документ US 20210058235 A1 2021.02.25
- Заявитель Landmark Graphics Corporation
- Автор Keshava Prasad Rangarajan
The predictive engine 104 can be used to generate optimal drilling paths and optimal production control variables based on data models, AI algorithms, and ML algorithms. The drilling patterns can be generated for consumer consumption to assist in and improve performance of drilling and production operations and/or the automation and improved performance, i.e. control and accuracy, of drilling and production equipment. The predictive engine 104 can comprise a drill path and production control pattern recognition component 106 and an ML engine 108. The pattern recognition component 106 can comprise an AI engine 132, a simulator 134, and an optimization engine 136. In an embodiment, the AI engine 132 can predict an earth model based on well log and seismic data variables collected from field device components 18, other input data, and an AI algorithm.
- CHROMIUM OXIDE CATALYST FOR ETHYLENE POLYMERIZATION
- МПК C08F210/16
- Документ WO 2018130539 A1 2018.07.19
- Заявитель SABIC GLOBAL TECHNOLOGIES B.V.
- Автор HAMED, Orass
The object is obtained by a solid catalyst system comprising a chromium compound, a metal compound, an aluminium compound and a silicon oxide support, wherein the silicon oxide support has an average particle diameter in the range between≥20 and≤50 μιη, a pore volume in the range between≥1.7 ml/g and≤3 ml/g, and a surface area in the range between≥400 m2/g and≤800 m2/g and wherein the aluminium alkoxide compound has the formula R1-AI-OR2 wherein R1 is selected from (C1-C8 ) alkyl groups and OR2 is selected from (C1-C8) alkoxyl groups. According to a preferred embodiment of the invention the pore radius of the silicon dioxide support is at least 100 Angstrom. The upper limit is 200 Angstrom. According to a preferred embodiment of the Invention the silica support has an average particle diameter in the range between≥30 and≤40 μιη, a pore volume in the range between≥1.7 ml/g and≤1.9 ml/g and a surface area in the range between≥500 m2/g and≤600 m2/g.
- AI/ML, DISTRIBUTED COMPUTING, AND BLOCKCHAINED BASED RESERVOIR MANAGEMENT PLATFORM
- МПК E21B41/00
- Документ WO 2021041252 A1 2021.03.04
- Заявитель LANDMARK GRAPHICS CORPORATION
- Автор RANGARAJAN, Keshava, Prasad
Various AI and ML based algorithms, to be discussed in reference to Figs. 3-6, include features that generate and predict a new optimum path (dynamically) from drill bit location to target location. When the drill bit deviates too much from originally planned path. This dynamic updating of new path also takes into account new information obtained by sensors located near the drill bit and which are relevant to updating of earth model from time to time. The various AI and ML based algorithms also include features for path planning; which are based on path searching in the presence of obstacles algorithm and pure pursuit algorithm. These particular generate control variables information for controlling altitude and trajectory of drill bit so as to follow the optimum path.
- SOFT HIGH-STRUCTURE CARBON BLACK
- МПК C09C1/48
- Документ JP 0007026163 A 1995.01.27
- Заявитель ASAHI CARBON KK
- Автор SATO HARUO
DBP吸油量は160~220ml/100gであるが、160ml/100gを下回った場合には引張り応力や引裂き強さなどの物理的特性が低下し、また220ml/100gの上限は表面積範囲がFEF級カーボンブラックではこの数値以上に上げることは困難であり、もし上げ得たとしてもその効果は飽和状態となって現われにくくなるために設定されたものである。1回圧縮後のDBP吸油量(A1)とDBP吸油量(A0)との比、A1/A0が0.82を下回った場合(特願昭57-10949号の請求範囲に重なる部分)には、カーボン配合比率が通常(50重量部配合)の場合には優れた特性を示すが、低配合比率(40重量部配合)の場合においてカーカス部材として要求される十分な引張り応力や引裂き強さなどの特性が得られなくなるからである。また、0.88を上回った場合には発熱性、反発弾性などの動的特性の低下がみられるので望ましくない。同様のことがストラクチャー強度Kに対してもいうことができ、Kが0.35を上回った場合では引張り応力や引裂き強さなどの特性が低下し、またKが0.25を下回ったときには動的特性の低下がみられる。水銀ポロシメトリーで測定したカーボンブラック表面の細孔の個数NがDBP吸油量とN2SA値から算出される値を下回った場合には引張り応力や引裂き強さなどの物理的特性が低下してしまう。Dstモード径は、カーボンブラックのゴムでの最小分散単位であるアグリゲートの大きさを遠心沈降分析により評価した場合の最多頻度値であるが、この値がN2SAの値から算出された値よりも小さい場合には発熱性、反発弾性などの動的特性が低下するので好ましくない。 【0009】本発明において適用されるカーボンブラックの物理化学的特性は、次のようにして測定される。 (1)DBP吸油量(A0) JIS K6221 6.1.2項A法に記載の方法で測定され、カーボンブラック100g当たりに吸収されるジブチルフタレート(DBP)のmlで表示される。 (2)24MiDBP吸油量(Ai) ASTM D3493-91に記載の方法で測定され、1687kgf/cm2の圧力でi回圧縮、ほぐし後の試料のDBP吸油量であり、ml/100gで表示される。 ...
- SYMBOLS INCORPORATION SCHEME FOR DFT-S-OFDM
- МПК H04L27/26
- Документ WO 2020021971 A1 2020.01.30
- Заявитель MITSUBISHI ELECTRIC CORPORATION
- Автор CIOCHINA, Cristina
Indeed, the samples in the radio signal of the symbol X, or of the symbol Ai can be obtained in different ways. [0021] For example, the symbols in the positions nj+mL in the block of symbols are respectively set to the value and the DFTsOFDM scheme is applied to the block of symbols (referred to as pre- DFT incorporation). [0022] In another example, the symbols in the positions nrHnL in the block of symbols are respectively set to 0 in the block of symbols, and the samples in the frequency domain of the symbols Ai are added at the output of the DFT, or at the input of the IDFT (referred to as post-DFT incorporation). [0023] In yet another example, the symbols in the positions nj+mL in the block of symbols are respectively set to 0 in the block of symbols, and the samples in the radio signal of the symbols A are added at the output of the IDFT (referred to as post-IDFT incorporation). [0024] However, like mentioned above, in all these cases the samples in the radio signal and the radio signal ...
- AI/ML, DISTRIBUTED COMPUTING, AND BLOCKCHAINED BASED RESERVOIR MANAGEMENT PLATFORM
- МПК G06N20/00
- Документ WO 2021041254 A1 2021.03.04
- Заявитель LANDMARK GRAPHICS CORPORATION
- Автор RANGARAJAN, Keshava, Prasad
Various AI and ML based algorithms, to be discussed in reference to Figs. 3- 6, include features that generate and predict a new optimum path (dynamically) from drill bit location to target location. When the drill bit deviates too much from originally planned path. This dynamic updating of new path also takes into account new information obtained by sensors located near the drill bit and which are relevant to updating of earth model from time to time. The various AI and ML based algorithms also include features for path planning; which are based on path searching in the presence of obstacles algorithm and pure pursuit algorithm. These particular generate control variables information for controlling altitude and trajectory of drill bit so as to follow the optimum path.
- AI/ML AND BLOCKCHAINED BASED AUTOMATED RESERVOIR MANAGEMENT PLATFORM
- МПК G06Q50/02
- Документ WO 2021041251 A1 2021.03.04
- Заявитель LANDMARK GRAPHICS CORPORATION
- Автор RANGARAJAN, Keshava Prasad
Various AI and ML based algorithms, to be discussed in reference to Figs. 3-6, include features that generate and predict a new optimum path (dynamically) from drill bit location to target location. When the drill bit deviates too much from originally planned path. This dynamic updating of new path also takes into account new information obtained by sensors located near the drill bit and which are relevant to updating of earth model from time to time. The various AI and ML based algorithms also include features for path planning; which are based on path searching in the presence of obstacles algorithm and pure pursuit algorithm. These particular generate control variables information for controlling altitude and trajectory of drill bit so as to follow the optimum path.
- SYSTEM AND METHOD FOR IMPROVING INDOOR COVERAGE OF CELLULAR RECEPTION USING A SMART TELEVISION
- МПК H04W16/20
- Документ US 20210235280 A1 2021.07.29
- Заявитель Saankhya Labs Pvt. Ltd.
- Автор Parag Naik
The Intelligent receiver includes an artificial intelligence (AI) or Machine learning (ML) based indoor coverage monitoring unit and, a Pico transmitter application. The AI/ML based indoor coverage monitoring unit continuously monitors at least one cellular reception factor of at least one indoor user device. The AI/ML based indoor coverage monitoring unit predicts an optimal indoor modulation profile that is required for the at least one indoor user device. The optimal indoor modulation profile is a mapping between a modulation parameter and indoor coverage that corresponds to the at least one indoor user device. The AI/ML based indoor coverage monitoring unit selects a required modulation index that corresponds to the predicted optimal indoor modulation profile required for the at least one indoor user device based on the at least one cellular reception factor and the indoor coverage.
- USING ARTIFICIAL INTELLIGENCE TO SELECT AND CHAIN MODELS FOR ROBOTIC PROCESS AUTOMATION
- МПК G06F8/60
- Документ US 20210200523 A1 2021.07.01
- Заявитель UiPath, Inc.
- Автор Prabhdeep SINGH
For example, some embodiments of the present invention pertain to using AI to select and/or chain models for RPA. In an embodiment, a computer-implemented method for using AI to select and/or chain ML models for RPA includes executing, by a computing system, a model of models that analyzes performance of individual ML models and chains of ML models in an ML model pool to be called in a workflow of an RPA robot. When superior performance to an existing ML model or chain of ML models is discovered by the model of models, the computer-implemented method also includes deploying the discovered ML model or chain of ML models, by the computing system, thereby replacing the existing ML model or chain of ML models. In another embodiment, a computer-implemented method for using AI to select and/or chain ML models for RPA includes executing a model of models that analyzes performance of individual ML models and chains of ML models in an ML model pool to be called in a workflow of an RPA robot.
- SYMBOLS INCORPORATION SCHEME FOR DFT-S-OFDM
- МПК H04L27/26
- Документ EP 3599748 A1 2020.01.29
- Заявитель Mitsubishi Electric R&D Centre Europe B.V.
- Автор CIOCHINA, Cristina
The value ρni+mL of the symbol Xni+mL is ej2πk(ni+mL)/MAi. Therefore, Xni+mL is one of the symbols of the block of symbols that conveys the symbol Ai. At the receiver side the symbol Ai can easily be retrieved from the samples of the symbols Xni+mL, with 0 ≤ m ≤ K. The symbol Ai is for example a modulation symbol like a QPSK modulation symbol or a symbol from a given sequence such as a CAZAC sequence or a symbol from a predefined sequence with controlled PAPR for example. The symbols Xni+mL are the symbol Ai with phase shift. The values, to which the symbols Xni+mL are set to, can be for examples phase shifted symbols of a digital modulation scheme, or phase shifted symbols taken from a CAZAC sequence or from another predefined sequence with controlled PAPR. Samples of the symbol Ai are the same than the samples of the symbols Xni+mL, with 0 ≤ m ≤ K. The index k and the integer K define the comb.
Описание
Область техники, к которой относится изобретение
Настоящее изобретение относится к области искусственного интеллекта и, в частности, к машинному обучению моделей для персонализации пользовательских устройств. В частности, заявляемое изобретение может быть использовано в целях распознавания объектов на изображениях, предсказания вводимых пользователем слов в сообщениях, распознавания речи, распознавания рукописного ввода, и в различных устройствах и приложениях, известных как интеллектуальные помощники.
Уровень техники
В источнике US 8,429,103 B1 (2012-06-22, Google Inc.) раскрыт способ обучения модели машинного обучения (ML), выполняемый на пользовательском устройстве, таком как мобильный телефон, с получением элементы данных от мобильных приложений или из сети. Способ машинного обучения может содержать определение по меньшей мере одного элемента данных на основании принятых данных и формирование выводимых данных путем выполнения операции машинного обучения на упомянутом по меньшей мере одном элементе данных. Выводимые данные могут передаваться в приложение, в сеть и т.п. Может быть предусмотрен механизм агрегации и представления данных (DARE), который постоянно принимает и сохраняет вводимые данные, при необходимости из множества источников. Сохраняемые вводимые данные могут агрегироваться для обнаружения элементов данных среди упомянутых данных. Например, в известных методиках машинного обучения могут использоваться алгоритмы поэтапного обучения, в которых для обучения требуются ограниченные объемы предшествующей информации или вовсе не требуется предшествующая информация. К недостаткам данного известного решения следует отнести ограниченность сферы его применения исключительно мобильными телефонами, необходимость сбора личных данных пользователя, а также риск так называемого «переобучения» модели (нежелательного явления, возникающего, когда вероятность ошибки обученного алгоритма на объектах тестовой выборки оказывается существенно выше, чем средняя ошибка на обучающей выборке).
В источниках H. Brendan McMahan et al.(2016) Communication-Efficient Learning of Deep Networks from Decentralized Data и Yujun Lin et al. (2018) Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training раскрыт подход к обучению так называемых моделей «глубокого обучения», при котором обучающие данные остаются распределенными среди мобильных устройств, и совместно используемая модель обучается посредством агрегирования локально вычисляемых на упомянутых мобильных устройствах обновлений. Для улучшения работы распределенного стохастического градиентного спуска используется несколько приемов, состоящих в передаче только обновлений с достаточно большими весовыми коэффициентами, коррекции момента, локальном усечении градиента, маскировании момента, локальном накоплении градиентов и менее агрессивном разреживании градиента на начальных этапах обучения. Данный подход был исследован в контексте обработки данных изображений, голосового и текстового ввода. К недостаткам такого известного подхода следует отнести «переобучение» модели на новых данных, необходимость ожидания пользователем окончания обучения до тех пор, пока он не получит модель с лучшими характеристиками, и ограниченность способа обучения стохастическим градиентным спуском (SGD).
Рассмотренный выше подход может быть принят в качестве ближайшего аналога заявляемого изобретения.
Раскрытие изобретения
Данный раздел, раскрывающий различные аспекты и варианты выполнения заявляемого изобретения, предназначен для представления краткой характеристики заявляемых объектов изобретения и вариантов его выполнения. Подробная характеристика технических средств и методов, реализующих сочетания признаков заявляемых изобретений, приведена ниже. Ни данное раскрытие изобретения, ни нижеприведенное подробное описание и сопровождающие чертежи не следует рассматривать как определяющие объем заявляемого изобретения. Объем правовой охраны заявляемого изобретения определяется исключительно прилагаемой формулой изобретения.
С учетом вышеуказанных недостатков уровня техники задача настоящего изобретения состоит в создании решения, направленного на устранение вышеуказанных недостатков, снижение риска нарушения безопасности личных данных пользователя и уменьшение затрат на передачу данных по сетевым соединениям в целях обучения моделей машинного обучения для персонализации пользовательских устройств. Кроме того, в заявляемом изобретении исключается риск «переобучения» модели, которое в данном случае также можно назвать «забыванием». Кроме того, предложенное решение позволяет выполнять группировку пользователей по тематикам их интересов. Технический результат, достигаемый заявляемым изобретением, состоит в повышении качества обучения персонализированных моделей искусственного интеллекта при предотвращении их «переобучения» и при сниженных затратах на передачу данных по сетевым соединениям.
Для решения упомянутой задачи, в соответствии с одним аспектом изобретение относится к способу распределенного обучения модели машинного обучения (ML) искусственного интеллекта (AI), содержащему этапы, на которых: a) инициализируют одну или более моделей машинного обучения (ML) на сервере; b) распространяют одну или более моделей ML среди одного или более пользовательских устройств (UE), соединенных с сервером посредством сети связи; c) накапливают данные, формируемые пользователем посредством пользовательского ввода, на каждом из одного или более UE в течение периода накопления данных; d) передают обучающие данные с сервера на одно или более UE; e) осуществляют обучение модели на каждом из одного или более UE на основании упомянутых собранных данных и упомянутых обучающих данных до выполнения критерия прекращения обучения; f) получают на сервере обученные модели ML от упомянутых одного или более UE; g) обновляют на сервере модель ML путем агрегации обученных моделей ML, полученных от одного или более пользовательских устройств; h) передают обновленные модели ML в одно или более UE; и i) повторяют этапы c) -h) один или более раз до получения модели ML, соответствующей одному или более критериям качества модели ML.
В варианте выполнения изобретения способ может дополнительно содержать этапы, на которых: идентифицируют группу персонализации для пользователя каждого из одного или более UE на основании данных, формируемых пользователем, собранных на упомянутом каждом из одного или более UE; группируют на сервере модели ML, полученные от UE из упомянутых одного или более UE, по группам персонализации; и передают обновленные модели ML, сгруппированные по группам персонализации, в UE, входящие в соответствующую группу персонализации.
В варианте выполнения, модель ML может быть выполнена с возможностью предсказания слов и словосочетаний при вводе пользователем текстового сообщения на UE, при этом формируемые пользователем данные представляют собой слова и словосочетания, вводимые пользователем. В варианте выполнения, модель ML может быть выполнена с возможностью распознавания предметов на изображениях, получаемых с одной или более камер UE, при этом формируемые пользователем данные представляют собой изображения с одной или более камер UE и/или метки, присваиваемые пользователем предметам, присутствующим на изображениях. В варианте выполнения, модель ML может быть выполнена с возможностью распознавания рукописного ввода, принимаемого от пользователя посредством сенсорного экрана UE и/или сенсорной панели UE, при этом формируемые пользователем данные представляют собой упомянутый рукописный ввод и/или выбор пользователем предлагаемых моделью ML вариантов символов и/или слов, основанных на рукописном вводе от пользователя. В варианте выполнения, модель ML может быть выполнена с возможностью распознавания голосового ввода, принимаемого от пользователя посредством одного или более микрофона UE, при этом формируемые пользователем данные представляют собой упомянутый голосовой ввод и/или выбор пользователем предлагаемых моделью ML вариантов слов и/или словосочетаний, основанных на голосовом вводе от пользователя. В варианте выполнения, модель ML может быть выполнена с возможностью распознавания одной или более характеристик окружения UE и/или одного или более действий пользователя, при этом одна или более характеристик окружения UE представляют собой одно или более из времени, даты, дня недели, освещенности, температуры, географического местоположения, пространственного положения UE, при этом формируемые пользователем данные представляют собой пользовательский ввод в одно или более программных приложений на UE. В варианте выполнения, обучающие данные могут включать в себя порцию общедоступных данных из исходной выборки.
В варианте выполнения, критерием прекращения обучения является достижение сходимости моделей ML среди одного или более UE. В варианте выполнения, критерием прекращения обучения является достижение моделью ML заданного значения характеристики качества модели ML. В варианте выполнения, критерием прекращения обучения является достижение заданного количества периодов обучения.
В соответствии с другим аспектом настоящего изобретения предложена система распределенного обучения модели машинного обучения (ML) искусственного интеллекта (AI), содержащая: сервер; и одно или более пользовательских устройств (UE), соединенных с сервером посредством сети связи; при этом сервер выполнен с возможностью: инициализации одной или более моделей машинного обучения (ML); распространения одной или более моделей ML среди одного или более пользовательских устройств (UE); передачи обучающих данных на одно или более UE; получения обученных моделей ML от одного или более UE; обновления модели ML путем усреднения обученных моделей ML, полученных от одного или более UE; передачи обновленных моделей ML в одно или более UE; и при этом одно или более UE выполнены с возможностью: накопления данных, формируемых пользователем посредством пользовательского ввода, в течение периода накопления данных; приема обучающих данных от сервера; обучения модели ML на основании упомянутых собранных данных и упомянутых обучающих данных до выполнения критерия прекращения обучения.
Еще в одном аспекте настоящее изобретение предусматривает машиночитаемый носитель, на котором сохранена компьютерная программа, которая при выполнении одним или более процессорами реализует способ распределенного обучения модели ML в соответствии с первым из вышеуказанных аспектов. Изобретательский замысел, лежащий в основе настоящего изобретения, может быть реализован также в виде других объектов, таких как компьютерная программа, компьютерный программный продукт, сервер, пользовательское устройство, система беспроводной связи и т.п.
Краткое описание чертежей
Чертежи приведены в настоящем документе для облегчения понимания сущности настоящего изобретения. Чертежи являются схематичными и выполнены не в масштабе. Чертежи служат исключительно в качестве иллюстрации и не предназначены для определения объема настоящего изобретения.
На Фиг. 1 показана последовательность операций способа распределенного обучения модели машинного обучения (ML) в соответствии с первым аспектом настоящего изобретения;
На Фиг. 2 проиллюстрирован процесс обучения моделей ML на пользовательских устройствах (UE) и накопления персонализированных моделей ML на сервере в соответствии с изобретением;
На Фиг. 3 схематично проиллюстрировано обучение модели ML на UE в соответствии с изобретением.
Осуществление изобретения
Машинное обучение представляет собой класс методов искусственного интеллекта, характерной чертой которых является не прямое решение задачи, а обучение в процессе применения решений множества сходных задач. В частном случае, ряд методов машинного обучения основаны на использовании нейросетей, однако существуют и другие методы, использующие понятие обучающей выборки. В контексте настоящего изобретения методы машинного обучения могут быть использованы, в качестве неограничивающего примера, для целей распознавания объектов (например, на изображениях), прогнозирования слов (например, в различных приложениях, в которых пользователь вводит сообщения или поисковые запросы через интерфейс приложения на пользовательском устройстве), интеллектуальной обработки изображений со сверхвысоким разрешением, распознавания речи (например, в приложениях, принимающих от пользователя голосовой ввод и преобразующих данные голосового ввода в текст), распознавания рукописного текста (например, в приложениях, принимающих пользовательский ввод путем написания букв и других символов на сенсорном экране пользовательского устройства посредством стилуса или пальца пользователя), а также в различных программных приложениях, известных как «интеллектуальные помощники».
В контексте настоящего изобретения предполагается, что пользовательское устройство содержит одну или более функций искусственного интеллекта, реализуемые, например, программными средствами. Система, содержащая такие функции искусственного интеллекта, выполнена с возможностью «обучения» посредством одной или более методик машинного обучения для персонализации возможностей пользовательского устройства, реализуемых в виде различных средств, служб, программных приложений и т.п., с учетом различных характеристик пользователя данного пользовательского устройства. В качестве неограничивающего примера, персонализация может быть основана, например, на лексиконе пользователя (определяемом, например, при составлении пользователем сообщений в приложениях мгновенного обмена сообщениями, электронной почты, SMS и т.п.), тематике интересов пользователя (определяемой, например, по поисковым запросам пользователя в различных поисковых системах), сведениях о веб-страницах, просматриваемых пользователем, частоте и длительности просмотров конкретных веб-страниц, и т.п. Для «обучения» модели машинного обучения необходимы данные, которые предпочтительнее всего собирать непосредственно на пользовательском устройстве, однако на сбор данных о пользователе и их передачу за пределы пользовательского устройства накладывается ряд ограничений, связанных с безопасностью личных данных пользователя, соблюдением тайны частной жизни («приватности») пользователя и т.п.
Традиционно обучение моделей искусственного интеллекта осуществляется на одном или более серверах. Однако с этим связаны, в частности, следующие проблемы: 1) система искусственного интеллекта может быть неспособной адаптироваться к локальным условиям конкретного пользовательского устройства, и 2) общественно доступные данные могут отличаться от реальных данных. Адаптация к локальным условиям конкретного пользовательского устройства, как правило, реализуется в виде адаптации к аппаратной части устройства, в частности к характеристикам имеющейся в нем камеры при решении задач распознавания объектов или обработки изображений со сверхвысоким разрешением, или к характеристикам одного или более микрофонов, содержащихся в устройстве, при решении задач распознавания речи. Адаптация к пользователю может осуществляться на основании определяемых интересов пользователя (например, при прогнозировании слов при наборе пользователем сообщений) или на основании голоса данного конкретного пользователя при решении задач распознавания речи.
Для решения вышеуказанных проблем адаптация системы искусственного интеллекта может осуществляться путем выполнения обучающих алгоритмов на пользовательском устройстве. Однако такому решению, в свою очередь, присущи другие проблемы, которые состоят в недостаточном объеме данных для выполнения полноценного обучения моделей в рамках пользовательского устройства и в невозможности сбора пользовательских данных для каждого конкретного пользователя на удаленном сервере (в частности, с учетом вышеуказанных соображений безопасности личных данных пользователя и неприкосновенности его частной жизни).
Данные проблемы, в свою очередь, решаются в настоящее время в уровне техники, описанном выше, посредством распределенного «дообучения» (которое также можно охарактеризовать как своего рода «тонкую настройку», далее будет называться обучением или дообучением) моделей искусственного интеллекта на множестве различных пользовательских устройств. Однако, как показано выше, известным в уровне техники решениям в данной области в настоящее время присущи проблемы, связанные с тем, что: 1) такое «дообучение» моделей искусственного интеллекта может приводить к ситуациям «переобучения» или «забывания» всех исходно заложенных в модель данных при адаптации модели под конкретного пользователя; 2) пользователи, их устройства и их окружение могут быть чересчур различными для возможности такого распределенного «дообучения» моделей на множестве устройств; и 3) такой подход связан с издержками, такими как высокие затраты на передачу данных по сетевым соединениям.
Предлагаемое изобретение было создано с учетом вышеуказанных проблем известного уровня техники. Для решения вышеуказанных проблем уровня техники предлагаются следующие средства, которые будут более подробно описаны ниже в настоящем подробном описании изобретения.
1) Для предотвращения «переобучения» и обеспечения безопасности личных данных и приватности пользователя при обучении моделей используется небольшой объем исходных обучающих данных.
2) Пользователей группируют в отдельные группы для получения новых персонализированных моделей для каждой группы пользователей.
3) При распределенном обучении моделей собирают модели, обученные на каждом устройстве с учетом вышеприведенных соображений, а не градиенты, как в ближайшем аналоге из уровня техники, рассмотренном выше.
С учетом вышеприведенных соображений задача, на решение которой направлено заявляемое изобретение, состоит в повышении качества обучения персонализированных моделей искусственного интеллекта при предотвращении их «переобучения» и при сниженных затратах на передачу данных по сетевым соединениям. Настоящее изобретение направлено по существу на создание средства постоянного обновления моделей машинного обучения на основании пользовательских данных, но без необходимости сбора каких-либо личных данных пользователя, при снижении затрат на передачу данных по сетевым соединениям, повышении устойчивости моделей и частоты их обновления.
Сначала при обучении моделей используется небольшой объем исходных обучающих данных, что позволяет предотвратить «переобучение» модели («забывание» базовой информации) на основании вновь получаемых данных. Затем каждый пользователь обучает модель на своем устройстве в течение нескольких периодов и отправляет обновленную модель машинного обучения на сервер, где выполняется усреднение моделей, полученных от пользовательских устройств. Таким образом каждый конечный пользователь постоянно получает обновления в виде более точных моделей машинного обучения, адаптированных на основании данных, сформированных множеством пользователей. За счет этого функции искусственного интеллекта в соответствующих приложениях на каждом пользовательском устройстве становятся более точными. Кроме того, предотвращается нарушение безопасности личных данных каждого пользователя, сохраняемых, например, в виде фотографий, сообщений, текстовых файлов, ссылок на веб-страницы, звуковых данных (захваченных посредством микрофона пользовательского устройства) и т.п. Предотвращается «забывание» обучаемой моделью базовой информации, полученной при обучении модели на общедоступных данных.
Согласно изобретению исходная модель машинного обучения (ML) для программного приложения, содержащего функцию искусственного интеллекта (AI) обучается на сервере на основании общедоступных данных. Исходная модель ML поставляется с устройством или устанавливается при осуществлении связи устройства с сетью связи в процессе исходного обучения. Затем следует период ожидания, пока пользователь не сформирует в процессе использования приложения, содержащего функцию искусственного интеллекта, на пользовательском устройстве достаточный объем данных, чтобы можно было осуществить адаптацию модели машинного обучения.
В соответствии со сформированными пользователем данными и другой информацией, к которой можно получить доступ (такой как, например, марка и модель пользовательского устройства) идентифицируется тип модели машинного обучения, подходящий для данного пользователя и его устройства. Формируются группы персонализации, исходя, в качестве примера, но не ограничения, из идентифицированного типа модели машинного обучения и/или типа, марки или модели пользовательского устройства, и/или интересов пользователя, определенных на основании данных, сформированных пользователем за время упомянутого периода ожидания с целью адаптации модели машинного обучения.
В соответствии с идентифицированным типом модели машинного обучения сервер направляет на пользовательское устройство текущую версию модели машинного обучения. При этом в предпочтительном варианте выполнения изобретения определенные версии моделей машинного обучения направляются только пользователям в пределах соответствующих определенных групп персонализации.
Для повышения защищенности личных данных пользователю передается порция общедоступных данных из исходной выборки, которые использовались для исходного обучения модели. Это также позволяет предотвратить «забывание» моделью машинного обучения исходных данных в случае «переобучения» модели на данных конкретного пользователя. Далее обучение модели производится на пользовательском устройстве, используя в качестве исходной модели ту модель ML, которая была передана с сервера на пользовательское устройство. При этом на данном этапе обучение производится до достижения сходимости моделей между различными пользовательскими устройствами, например, в рамках одной группы индивидуализации либо до достижения некоторого максимального количества итераций обучения, которое устанавливается заранее.
Каждое устройство, в котором обучение модели ML завершается, отправляет свою обученную модель ML на сервер (такой как центральный сервер и/или сервер агрегации моделей). Персонализированные модели, обученные на различных пользовательских устройствах (например, в рамках одной группы индивидуализации) агрегируются на упомянутом сервере. Агрегация реализуется, например, путем создания усредненной модели. В результате агрегации получается новая версия модели определенного типа. Данная новая версия модели передается на пользовательские устройства в рамках соответствующей группы индивидуализации.
Описанная выше операция передачи пользователю порции общедоступных данных из исходной выборки, которые использовались для исходного обучения модели, с достижением преимущества предотвращает «переобучение» модели на новых данных на пользовательском устройстве и гарантирует приватность пользователя, не позволяя третьим лицам установить данные, которые характеризуют личность пользователя, например, в случае перехвата отправляемой на сервер персонализированной модели ML. Порция исходных обучающих данных передается на каждое из пользовательских устройств, и процедура обучения модели ML на каждом пользовательском устройстве выполняется с объединением данных, собранных на данном пользовательском устройстве, и упомянутых исходных данных, переданных на пользовательское устройство. В адаптации модели ML на пользовательском устройстве задействована лишь небольшая часть доступных пользовательских данных по сравнению с объемом исходных обучающих данных.
В традиционных решениях, в которых отсутствует операция добавления порции исходных обучающих данных в процессе обучения модели ML, это в определенный момент приводит к «переобучению» модели ML на данном пользовательском устройстве, которое характеризуется «забыванием» моделью ML всей информации, которая была ранее сохранена в модели ML. В результате такая «переобученная» модель не способна, например, адекватно предсказывать слова по пользовательскому вводу в сценарии использования «виртуальной клавиатуры» в приложении по обмену сообщениями, если контекст набираемого пользователем сообщения отличается от тех привычных контекстов, в которых ранее накапливались данные для обучения персонализированной модели машинного обучения на данном пользовательском устройстве.
При этом в предпочтительном варианте реализации предлагаемого решения объемы данных исходной выборки и выборки данных, формируемых пользователем, и используемые при обучении модели ML на данном пользовательском устройстве, находятся в соотношении 1:1. Это обеспечивает оптимальный баланс между новыми данными (т.е. данными, формируемыми пользователем данного пользовательского устройства) и исходными данными (данными, получаемыми от сервера) при обучении модели ML. Так модель ML «получает» новую информацию без «забывания» исходной информации. Если упомянутое соотношение будет составлять, например, 1:2, то баланс сместится в сторону «новых» данных (данных, формируемых пользователем), что приведет к «забыванию» исходных данных. Однако следует понимать, что упомянутое выше соотношение используется в предпочтительном варианте выполнения изобретения, которым объем настоящего изобретения не ограничивается, и в других вариантах выполнения изобретения, например, упомянутое соотношение может быть различным для различных пользователей на основании определенных критериев, характеризующих «поведение» каждого конкретного пользователя. В некоторых вариантах выполнения изобретения, например, различным пользователям могут присваиваться различные коэффициенты на основании «вклада» формируемых ими данных в обучение модели ML, например, в рамках определенной группы индивидуализации.
Для получения такой «совмещенной» модели, основанной как на данных, формируемых пользователем конкретного пользовательского устройства, так и на данных исходной обучающей выборки, может использоваться любая из известных в данной области техники процедур машинного обучения. В качестве примера, можно привести следующие источники, описывающие процедуры машинного обучения, подходящие для использования в контексте настоящего изобретения:
Bishop, C. M. (2006) "Pattern recognition and Machine Learning", Springer Science, p.232-272; и Mozer, M. C. (1995). "A Focused Backpropagation Algorithm for Temporal Pattern Recognition". In Chauvin, Y.; Rumelhart, D. Backpropagation: Theory, architectures, and applications. ResearchGate. Hillsdale, NJ: Lawrence Erlbaum Associates. pp. 137-169.
Обучение модели ML на устройстве выполняется до тех пор, пока не будет выполнено условие прекращения обучения на устройстве, такое как достижение сходимости моделей ML среди устройств, в предпочтительном варианте выполнения - в рамках определенной группы индивидуализации. После этого обученные модели ML передаются на сервер, где они агрегируются (в качестве неограничивающего примера, посредством усреднения моделей ML).
В качестве альтернативы или дополнения, критерием прекращения обучения модели ML может быть достижение моделью ML заданного значения характеристики качества модели ML, которая может быть сформулирована в терминах точности предсказания или классификации в зависимости от задачи: так, в задаче предсказания последующего слова можно оценивать точность предсказания слова; в задаче распознавания рукописного текста можно оценивать побуквенную или пословную точность распознавания текста и т.д. Специалистам в данной области техники будут очевидны различные способы оценки качества модели ML в зависимости от задачи, решаемой моделью, основываясь на вышеприведенных примерах.
Модель может передаваться на сервер не полностью, а лишь частично: те параметры модели, изменение которых относительно предыдущей итерации модели не превысило некоторого заданного порогового значения, могут не передаваться на сервер. В этом случае при усреднении будет использовано значение параметра из предыдущей итерации модели. Пороговое значение для принятия решения об отправке модели ML с пользовательского устройства на сервер может определяться, например, исходя из баланса между требованиями к точности модели ML и ограничениями на объемы передаваемых данных по сетевым соединениям между пользовательскими устройствами и сервером.
Обновление персонализированных моделей может осуществляться, например, на основании усреднения моделей.
Вместо вычисления и передачи градиентов для стохастического градиентного спуска, как в случае с рассмотренным выше ближайшим аналогом из уровня техники, авторы настоящего изобретения предлагают выполнять обучение модели ML на пользовательском устройстве до того момента, пока не будет выполняться какой-либо из заданных критериев прекращения обучения. В качестве примера, критерием может стать достижение заданного максимального количества периодов обучения модели ML или достижение определенной сходимости моделей по процедуре оптимизации. В качестве альтернативы или дополнения к вышеуказанному возможны и другие критерии прекращения обучения модели ML, которые могут быть предусмотрены специалистами в данной области техники по прочтении настоящего описания изобретения.
Это позволяет снизить потребность в обмене данными по сетевым соединениям между пользовательским устройством и сервером для осуществления процесса распределенного обучения моделей ML, снижая таким образом экономическую нагрузку на пользователя.
В некоторых вариантах выполнения настоящего изобретения при распределенном обучении моделей ML может быть дополнительно повышена эффективность предсказания обучаемой моделью редких слов, событий или объектов. Это может быть достигнуто за счет изменения критериев обучения. Дело в том, что редкие классы (слова, объекты и т.п.) на большинстве пользовательских устройств, участвующих в распределенном обучении моделей ML, возникают относительно нечасто, что приводит к их игнорированию в процессе обучения моделей ML и, в свою очередь, к плохим результатам предсказания для таких классов. Изменение критериев обучения моделей ML может быть эффективным при преодолении данной проблемы, если новые критерии будут чувствительны к таким классам с низкой вероятностью возникновения.
В качестве примера, среди стандартных критериев обучения можно выделить, например, функцию потерь от перекрестной энтропии между истинным распределением классов (p) и распределением (q), которое присваивается классам данной моделью. Данный критерий можно проиллюстрировать следующим выражением, приведенным ниже:
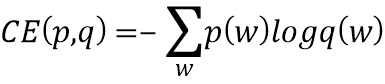
В соответствии с настоящим изобретением предлагается использование при обучении нового критерия, представляющего собой сумму перекрестной энтропии между вышеуказанными p и q и расстоянием Кульбаха-Лейблера между q и p:
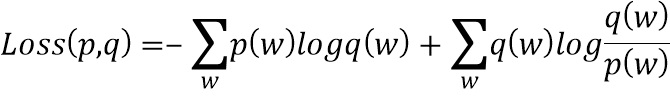
В вышеуказанной формуле к предсказаниям модели q(w) применяется штрафной коэффициент в случае, если дополнительная оценка истинной вероятности p(w) значительно ниже q(w). Оценка p(w) может быть получена из дискриминантного алгоритма, обученного отделению реальных данных от данных, отобранных из модели q(w), методами, известными специалистам в данной области техники. Применение такого подхода позволяет повысить точность предсказания в случае с редкими классами до 1,5%, и приводит к общему повышению точности предсказания до 0,2%.
В соответствии с вышеописанными операциями заявляемого способа пользователей группируют в различные группы индивидуализации, в частности, по следующим критериям: тематике текстовых сообщений, формируемых пользователем, географическому местоположению пользователя, его возрасту, типу аппаратного обеспечения, на котором выполняются одно или более программных приложений, в которых используются одна или более функций искусственного интеллекта. Следует понимать, что вышеуказанные критерии группировки пользователей в группы индивидуализации являются лишь неограничивающим примером, и специалистам в данной области техники будет понятно, что возможны и другие критерии группировки пользователей в группы индивидуализации в качестве альтернативы или дополнения к вышеуказанным. Кроме того, пользователи могут объединяться в группы индивидуализации, например, исходя из:
- технических параметров пользовательского устройства: размер дисплея, объем оперативной памяти, тип процессора и т.п.;
- географического местоположения устройства;
- информационного содержимого, формируемого пользователем, например, на веб-страницах (оценки, комментарии, ответы, заметки, публикации и т.п.);
- демографическим метаданным (пол пользователя, возраст, семейное положение, гражданство).
Согласно изобретению желательно иметь отдельные модели ML для различных групп пользователей или пользовательских устройств. Для идентификации группы индивидуализации, к которой следует отнести пользователя конкретного пользовательского устройства, на пользовательском устройстве может быть выполнен модуль классификации. Входными данными для модуля классификации может быть, не ограничиваясь, по меньшей мере одно из:
- данных, формируемых пользователем на устройстве;
- модели устройства;
- демографических данных, относящихся к пользователю;
- отметок географического местоположения, и т.п.
Количество групп индивидуализации может быть определено вручную или посредством любой подходящей методики кластеризации. Каждая группа индивидуализации соответствует одной модели ML или одному типу моделей ML.
Точность модели, относящейся к соответствующей конкретной группе, будет выше, чем точность модели, общей для всех групп. Так, в качестве неограничивающего примера, пользователи, которые обсуждают посредством текстовых сообщений в различных программных приложениях на своих мобильных устройствах темы, относящиеся к науке или технике, будут получать более точные предсказания слов на свою тематику при наборе сообщений в программных приложениях на своих пользовательских устройствах, поскольку персонализированная модель ML на их пользовательских устройствах будет основана только на данных, полученных от пользователей с аналогичными интересами.
Агрегирование множества моделей ML от пользователей, объединенных в общую группу индивидуализации, решает проблему малого размера выборки данных для обучения моделей ML. Однако при этом модели ML остаются персонализированными в том смысле, что для каждой группы индивидуализации пользователей формируется и обновляется своя модель ML. В результате пользователи в рамках определенной группы индивидуализации получают более точные персонализированные модели ML, основанные на их интересах, привычках, особенностях и/или характеристиках их аппаратного и/или программного обеспечения.
В варианте выполнения настоящего изобретения различным пользователям могут быть присланы модели с различными архитектурами (различными алгоритмами машинного обучения), и на основании результатов обучения моделей могут идентифицироваться модели с наилучшей архитектурой. Для этих целей на стороне сервера может быть предусмотрен дополнительный блок для формирования новых архитектур моделей ML и гиперпараметров для этих моделей. Любая система AI может также при необходимости быть расширена путем включения дополнительных функций, позволяющих испытывать новые модели ML на данных, формируемых пользователями.
Настоящее изобретение реализуется в стандартной архитектуре сетей беспроводной связи и включает в себя аппаратные и/или программные средства на стороне сервера и аппаратные и/или программные средства на стороне пользовательского устройства. К средствам на стороне сервера можно отнести, в качестве неограничивающего примера, блоки и/или модули, выполняющие описанные выше операции обеспечения исходных моделей ML, инициализации моделей машинного обучения (ML) на сервере, распределения (рассылки) модели (моделей) ML среди одного или более пользовательских устройств (UE), соединенных с сервером посредством сети связи, передачи обучающих данных исходной выборки с сервера на одно или более UE, приема моделей ML, обученных на одном или более UE, от одного или более UE, обновления на сервере персонализированной модели ML путем усреднения обученных моделей ML, принятых от одного или более UE. Вышеуказанные блоки и/или модули выполнены с возможностью повторения выполняемых ими операций любое необходимое количество раз, в зависимости от того, сколько повторений вышеописанных операций необходимо для получения одной или более персонализированных моделей ML, обладающих требуемой точностью и эффективностью.
На стороне пользовательского устройства при реализации настоящего изобретения также используется ряд аппаратных и/или программных модулей и/или блоков. В качестве неограничивающего примера, можно предусмотреть блок формирования пользовательского интерфейса, обеспечивающий пользовательский интерфейс, позволяющий пользователю управлять UE. UE может включать в себя различные средства ввода-вывода (I/O), такие как, не ограничиваясь, сенсорный экран, одну или более клавиш, один или более микрофонов, одну или более фото- и/или видеокамер, приемник(и) сигналов системы позиционирования, такой как GPS, GLONASS, GALILEO и т.п., один или более датчиков для определения физических параметров пользовательского устройства и/или его окружения, таких как пространственное положение пользовательского устройства, температура, уровень освещенности и т.п., один или более громкоговорителей. Специалистам в данной области техники будет понятно, что вышеприведенный перечень средств I/O приведен лишь в качестве иллюстративного примера и не является исчерпывающим, и что в зависимости от конкретной реализации пользовательского устройства может быть предусмотрено любое подходящее сочетание вышеупомянутых и/или любых других средств I/O.
Далее в пользовательском устройстве могут быть предусмотрены различные блоки и/или модули распознавания текста, распознавания рукописного ввода, анализа изображений, распознавания образов на изображениях, распознавания отпечатков пальцев, анализа голосового ввода, преобразования голосового ввода в текст, синтаксического и/или статистического анализа естественного языка, формирования текста на естественном языке, преобразования текста в голосовой вывод, и т.п. Следует понимать, что данный перечень возможных блоков и/или модулей, которые позволяют обрабатывать данные, вводимые в пользовательское устройство средствами I/O, не является исчерпывающим, и что в зависимости от конкретных вариантов реализации заявляемого изобретения могут быть предусмотрены и другие средства обработки вводимых данных и/или обработки данных для вывода, в качестве дополнения или альтернативы к перечисленным.
Упомянутые блоки и/или модули обработки данных передают данные, извлеченные из пользовательского ввода, принятого средствами I/O в одну или более функций AI, реализующих одну или более моделей машинного обучения (ML) в одном или более программных приложениях, выполняемых в пользовательском устройстве. Одна или более моделей ML принимают упомянутые данные от блоков и/или модулей обработки данных и используют эти данные, в частности, для формирования вывода в ответ на данные, принятые от пользователя, а также для собственного обучения. Так, например, выводом в ответ на пользовательский текстовый ввод посредством экранной клавиатуры или одной или более клавиш может быть предлагаемый моделью ML вариант предсказания пользовательского ввода в виде одного или более вариантов слова или словосочетания, которые пользователь, вероятно, желает ввести в окне набора текстового сообщения. В варианте реализации, в котором модель ML используется для распознавания образов на изображениях, в ответ на изображение с камеры пользовательского устройства модель ML может выдавать в виде текста на экране пользовательского устройства один или более вариантов названия предмета или предметов, распознанных моделью ML на введенном изображении. В варианте реализации, в котором распознается пользовательский голосовой ввод, модель ML может преобразовывать данные голосового ввода в текст на естественном языке, который далее может быть подвергнут анализу (например, синтаксическому анализу), после чего модель ML выдаст данные в виде вывода текстового сообщения на экране, повторяющего пользовательский голосовой ввод, вывода на экране пользовательского устройства результатов поиска в поисковой системе и/или на географической карте, если пользовательский голосовой ввод распознается в качестве поискового запроса в приложение, реализующее доступ к одной или более поисковым системам и/или в приложение, обеспечивающее доступ к географическим картам, отображение местоположения пользователя, прокладку навигационных маршрутов и т.п. В варианте реализации, в котором модель ML распознает рукописный ввод, в ответ на пользовательский ввод в виде движения по поверхности сенсорного экрана, например, одним или более пальцев или стилусом, модель ML может выводить предлагаемые варианты одного или более распознанных символов, слов или предложений на основании пользовательского ввода.
Следует отметить, что одна или более моделей ML может быть реализована программным средством, таким как компьютерная программа и/или один или более компьютерных программных элементов, модулей компьютерной программы, компьютерный программный продукт и т.п., выполненные на одном или более языках программирования или в виде машиноисполняемого кода. Кроме того, одна или более моделей ML согласно изобретению могут быть реализованы с применением различных аппаратных средств, таких как программируемые пользователем вентильные матрицы (FPGA), интегральные схемы, и тому подобное. Специалистам в данной области техники будут очевидны различные конкретные примеры программных и/или аппаратных средств, пригодных для реализации одной или более моделей ML, в зависимости от конкретной реализации предлагаемого изобретения.
Для осуществления связи между сервером и UE могут быть предусмотрены один или более известных в данной области техники блоков, посредством которых осуществляется передача и прием данных, их кодирование и декодирование, скремблирование, шифрование, преобразование и т.п. Связь UE с сервером может осуществляться посредством одной или более сетей связи, работающих на основе любой известной специалистам в данной области техники технологии беспроводной связи, такой как GSM, 3GPP, LTE, LTE-A, CDMA, ZigBee, Wi-Fi, Machine Type Communication (MTC), NFC и т.п., или на основе любой известной специалистам в данной области техники технологии проводной связи. Средства передачи и приема данных для связи между сервером и UE не ограничивают объем настоящего изобретения, и в зависимости от его конкретной реализации специалистами в данной области техники может быть предусмотрено сочетание из одного или более средств приема и передачи данных.
В одном или более вариантах выполнения настоящего изобретения также может быть предусмотрен модуль оценки моделей ML. Такой модуль может быть предусмотрен, в частности, на сервере. На основании оценки моделей ML, которые сервер принимает с различных пользовательских устройств, моделям ML с различных пользовательских устройств могут присваиваться различные весовые коэффициенты. Оценивается качество одной или более моделей ML, предпочтительно в рамках каждой конкретной группы индивидуализации, к которой относятся собранные с пользовательских устройств одна или более моделей ML. На основании оценки моделям ML могут быть присвоены весовые коэффициенты, в соответствии с которыми может далее выполняться обновление на сервере персонализированной модели ML путем усреднения моделей ML, принятых от одного или более UE, с учетом присвоенных им весовых коэффициентов. В вариантах выполнения настоящего изобретения при усреднении могут использоваться не все модели ML, собранные с пользовательских устройств, например, в рамках конкретной группы индивидуализации, а только те модели, весовые коэффициенты которых превышают определенное заданное пороговое значение или находятся в рамках определенного диапазона, ограниченного верхним и нижним пороговыми значениями, или в наибольшей степени приближаются к определенному заданному значению, в зависимости от конкретной реализации заявляемого изобретения.
Работа изобретения была экспериментально проверена для частного случая распределенного дообучения модели предсказания следующего слова для экранной клавиатуры мобильного телефона. В эксперименте в качестве модельных данных, используемых для обучения исходной модели использовались тексты сайта Wikipedia. Исходная модель обучалась на виртуальном сервере (далее ВС). В качестве модельных пользовательских данных использовались сообщения, взятые из корпуса Twitter. Тексты Twitter были случайным образом распределены по виртуальным узлам (далее ВУ), заменяющим мобильные устройства. Далее исходная модель рассылалась на ВУ вместе с порцией исходных данных Wikipedia. Соотношение порций Twitter и Wikipedia на ВУ: 1:1 (по 10 Кб). На получившихся 20 Кб текста запускался алгоритм обучения рекуррентной нейронной сети до сходимости, после чего модели, обученные на каждом из ВУ, отправлялись на ВС, где усреднялись. Модель на ВС обновлялась и процесс повторялся, причем на каждом из ВУ порция данных из Twitter обновлялась для имитации набора новой порции сообщений пользователем.
Эксперимент показал, что после 300 итераций описанного выше алгоритма качество предсказания следующего слова на текстах Twitter, оцениваемого в терминах среднего количества нажатий на клавиатуре, улучшилось на 8,5 процентных пунктов. При этом качество предсказаний на текстах Wikipedia почти не изменилось, что говорит о том, что «забывания» удалось избежать.
Кроме того, для описываемого выше метода были экспериментально проверены гарантии уровня приватности, измеренные в терминах дифферанциальной приватности (differential privacy). Экспериментальная оценка уровня приватности указывает на то, что вероятность раскрытия пользовательских данных крайне мала и как минимум не уступает другим аналогичным методам распределенного обучения.
Работа настоящего изобретения будет пояснена ниже на иллюстративном варианте выполнения, приведенном исключительно в качестве примера, но не ограничения.
Рассмотрим последовательность операций способа распределенного обучения модели машинного обучения (ML) искусственного интеллекта (AI) согласно первому из вышеперечисленных аспектов настоящего изобретения.
В соответствии со способом согласно изобретению, на этапе S1 инициализируют одну или более моделей машинного обучения (ML) на сервере. Инициализация может включать в себя обучение упомянутых одной или более моделей ML на основании исходной выборки обучающих данных, которые представляют собой общедоступные данные.
Далее, на этапе S2 распространяют упомянутые инициализированные одну или более моделей ML среди одного или более пользовательских устройств (UE), соединенных с сервером посредством сети связи. Распространение может быть реализовано посредством передачи данных упомянутых одной или более моделей ML с сервера на одно или более UE при помощи любых средств, известных в области беспроводной передачи данных. В качестве альтернативы, модели ML могут распространяться и другими средствами, в частности по проводным сетям, на съемных машиночитаемых носителях и т.п.
На этапе S3 на каждом из одного или более UE накапливают данные, формируемые пользователем посредством пользовательского ввода. Данные формируются пользователем в процессе использования одного или более программных приложений, установленных на UE, а также в процессе передачи сообщений, осуществления вызовов по одной или более сетям связи и т.п. В качестве примера, обучаемая модель ML может быть выполнена с возможностью предсказания слов и словосочетаний при вводе пользователем текстового сообщения на UE. При этом формируемые пользователем данные, накапливаемые на этапе S3, могут представлять собой, например, слова и словосочетания, вводимые пользователем при составлении текстовых сообщений, заметок, записей и т.п. В качестве другого примера, модель ML может быть выполнена с возможностью распознавания предметов на изображениях, получаемых с одной или более камер UE. В таком случае, формируемые пользователем данные представляют собой изображения, которые пользователь формирует посредством одной или более фото- или видеокамер, предусмотренных в UE, а также метки, присваиваемые пользователем предметам, присутствующим на изображениях. Кроме изображений с одной или более камер UE распознавание образов может выполняться моделью ML также и на изображениях, которые UE получает из других источников, например принимает посредством сети связи в сообщениях от других пользователей или при просмотре веб-сайтов.
В другом примере, модель ML может быть выполнена с возможностью распознавания рукописного ввода, принимаемого от пользователя посредством сенсорного экрана UE и/или сенсорной панели UE. В таком случае формируемые пользователем данные могут представлять собой рукописный ввод, выполняемый пользователем посредством упомянутого сенсорного экрана и/или сенсорной панели при помощи, например, одного или более пальцев или стилуса, а также выбор пользователем предлагаемых моделью ML вариантов символов и/или слов, основанных на рукописном вводе от пользователя, которые UE отображает на экране при выполнении соответствующего программного приложения.
В другом примере, модель ML может быть выполнена с возможностью распознавания голосового ввода, принимаемого от пользователя посредством одного или более микрофонов, предусмотренных в UE, при этом формируемые пользователем данные представляют собой упомянутый голосовой ввод и/или выбор пользователем предлагаемых моделью ML вариантов слов и/или словосочетаний, основанных на голосовом вводе от пользователя, которые UE отображает на экране при выполнении соответствующего программного приложения.
Еще в одном примере, модель ML может быть выполнена с возможностью распознавания одной или более характеристик окружения UE и/или одного или более действий пользователя. Характеристики окружения UE могут представлять собой, не ограничиваясь, время, дату, день недели, уровень освещенности, температуру воздуха, уровень влажности воздуха, географическое местоположение UE, пространственное положение UE. При этом формируемые пользователем данные представляют собой пользовательский ввод в одно или более программных приложений на UE. В данном примере модель ML может предлагать пользователю, например, различные действия в управлении различными программными приложениями на UE и/или автоматически вызывать выполнение определенных действий в упомянутых программных приложениях.
Формируемые пользователем данные накапливаются на UE в течение заданного периода накопления данных. Когда накапливаемые на UE пользовательские данные достигают заданного объема, UE может передавать на сервер сообщение о том, что накоплен необходимый объем данных.
На этапе S4 сервер передает на UE обучающие данные, которые представляют собой порцию выборки исходных данных, использовавшихся на этапе S1 при первоначальном обучении модели ML. Эти данные являются общедоступными и не характеризуют конкретного пользователя. Использование выборки исходных данных при обучении модели ML позволяет гарантировать безопасность личных данных пользователя и предотвратить «переобучение» модели ML на UE.
Далее на этапе S5 осуществляют обучение модели ML на каждом из одного или более UE на основании упомянутых собранных данных и упомянутых обучающих данных до выполнения критерия прекращения обучения. В качестве критерия прекращения обучения, в качестве неограничивающего примера, может выступать достижение сходимости моделей ML среди одного или более UE, либо достижение моделью ML заданного значения характеристики качества модели ML, либо достижение заданного количества периодов обучения модели ML.
На этапе S6 получают на сервере обученные модели ML от упомянутых одного или более UE. Данная операция представляет собой передачу моделей ML, прошедших обучение на соответствующих UE, например, на сервер посредством сети беспроводной связи. Сервер собирает обученные на различных UE модели ML.
На этапе S7 сервер обновляет модель ML путем усреднения обученных моделей ML, полученных от одного или более UE. В качестве неограничивающего примера, упомянутое обновление модели ML может состоять в агрегировании персонализированных моделей ML, полученных от одного или более UE, на сервере. В результате агрегации получается новая версия модели ML, основанная на персонализированных моделях ML, обученных на одном или более UE и собранных на сервере.
На этапе S8 полученная посредством усреднения новая версия модели ML передается сервером в одно или более UE. Данная передача осуществляется, в качестве неограничивающего примера, общеизвестными средствами сети беспроводной связи.
Этапы S3-S8 могут повторяться один или более раз, например, до получения модели ML, соответствующей одному или более критериям качества модели ML. В результате получается персонализированная модель ML, «дообученная» на основании данных, формируемых пользователями различных UE, а также выборки исходных данных, применяемых при первоначальном обучении модели ML на сервере.
По меньшей мере в одном из вариантов выполнения изобретения способ может дополнительно содержать этап идентификации одной или более групп персонализации для пользователей каждого из одного или более UE на основании данных, формируемых пользователем, собранных на упомянутом каждом из одного или более UE. Далее, согласно упомянутому по меньшей мере одному из вариантов выполнения, способ содержит группирование на сервере моделей ML, полученных от упомянутых одного или более UE, по группам персонализации; и передачу обновленных моделей ML, сгруппированных по группам персонализации, только в UE, входящие в соответствующую группу персонализации. Таким образом обеспечивается дополнительная персонализация обучаемых моделей ML и повышается точность моделей ML для различных групп пользователей.
Специалистам в данной области техники будет понятно, что выше описаны и показаны на чертежах лишь некоторые из возможных примеров технических приемов и материально-технических средств, которыми могут быть реализованы варианты выполнения настоящего изобретения. Специалистам в данной области техники также будет понятно, что этапы описанного в настоящем документе способа не обязательно выполняются в той последовательности, в которой они описаны, а по меньшей мере некоторые из этапов способа могут выполняться в порядке, отличном от описанного, в том числе по существу одновременно, или некоторые этапы могут быть пропущены. Приведенное выше подробное описание вариантов выполнения изобретения не предназначено для ограничения или определения объема правовой охраны настоящего изобретения.
Другие варианты выполнения, которые могут входить в объем настоящего изобретения, могут быть предусмотрены специалистами в данной области техники после внимательного прочтения вышеприведенного описания с обращением к сопровождающим чертежам, и все такие очевидные модификации, изменения и/или эквивалентные замены считаются входящими в объем настоящего изобретения. Все источники из уровня техники, приведенные и рассмотренные в настоящем документе, настоящим включены в данное описание путем ссылки, насколько это применимо.
При том, что настоящее изобретение описано и проиллюстрировано с обращением к различным вариантам его выполнения, специалистам в данной области техники будет понятно, что в нем могут быть выполнены различные изменения в его форме и конкретных подробностях, не выходящие за рамки объема настоящего изобретения, который определяется только нижеприведенной формулой изобретения и ее эквивалентами.
Автор(ы) %
- Kia Silverbrook 351
- BACHER, Gerald 310
- CAVALLI, Fabio 310
- CAVALLI, Vera 309
- BEVEC, Dorian 307
- Aya Jakobovits 159
- STOESSEL, Philipp 132
- Craig Rosen 118
- Steven Ruben 108
- Harpreet Singh 107
- Andrea Mahr 106
- Jens Fritsche 106
- Toni Weinschenk 104
- RUBEN, Steven, M. 96
- ILG, Kerstin 96
- CUSTODERO, Emmanuel 96
- Andrea MAHR 95
- Arthur B. Raitano 89
- Oliver Schoor 88
- ROSEN, Craig, A. 88
- EBERLE, Thomas 88
- Toni WEINSCHENK 82
- Harpreet SINGH 81
- Jens FRITSCHE 81
- BOUALLEG, Malika 80
- PFLUMM, Christof 76
- ABAD, Vincent 76
- Rene S. Hubert 75
- Mary Faris 74
- Yutaka Murakami 72
- GÖRGENS, Ulrich 72
- Carla N. Yerkes 71
- FISCHER, Reiner 69
- Oliver SCHOOR 67
- Lee 67
- DUBOIS, Jean-Luc 66
- Aesop Cho 64
- JATSCH, Anja 63
- Yutaka MURAKAMI 62
- Paul R. Schmitzer 58
- Tiago Paiva 58
- PARHAM, Amir Hossain 58
- Simon Robert Walmsley 56
- SUAU, Jean-Marc 56
- Mikihiro OUCHI 55
- Tomohiro KIMURA 55
- BARASH, Steven, C. 54
- Mikihiro Ouchi 53
- Tomohiro Kimura 53
- Simon Walmsley 51
- BOTTO, Jean-Marie 51
- Charles Howard Cella 50
- Kunihiko Kodama 50
- HOFFMAN, Thomas, James 48
- Li Li 48
- Pamela Tan 48
- Akinori Shibuya 47
- STIERLI, Daniel 47
- Kim 47
- Shinichi Kanna 46
- Steven Barash 46
- BUESING, Arne 46
- MÜLLER, Ulrich 45
- NESTERENKO, Nikolai 45
- Arthur Raitano 44
- Jun Hatakeyama 44
- ARAUJO DA SILVA, José-Carlos 44
- Kimberly Spytek 43
- Takeshi Kinsho 43
- DIETRICH, Hansjörg 43
- Breton, Lionel 43
- COUTURIER, Jean-Luc 43
- The designation of the inventor has not yet been filed 42
- ARMAND, Michel 42
- Daniel Afar 40
- Meera Patturajan 40
- Seo 40
- BIBETTE, Jérôme 40
- DOMLOGE, Nouha 40
- Park 39
- Akin Akinc 38
- Akiyoshi GOTO 38
- HEIL, Holger 38
- Aaron Dodd 37
- CHOI, Jinsoo 37
- Jafar Adibi 37
- Vega Masignani 37
- TURBERG, Andreas 37
- AMEDURI, Bruno 37
- ARAUJO DA SILVA, José Carlos 37
- BACQUE, Eric 37
- Adrian Russell 36
- Dieter Feucht 36
- Xiaojia Guo 36
- BRUDER, Friedrich-Karl 36
- DAHMEN, Peter 36
- GATZWEILER, Elmar 36
- Craig A. Rosen 35
- Koji Hasegawa 35
- Norbert M. Satchivi 35
Патентообладатель(и) %
- FUJIFILM Corporation 825
- The Regents of the University of California 384
- Centre National de la Recherche Scientifique 380
- Compagnie Générale des Etablissements Michelin 274
- Dow AgroSciences LLC 270
- BASF SE 261
- Aventis Pharma S.A. 261
- RHODIA CHIMIE 258
- Commissariat à l'Énergie Atomique et aux Énergies Alternatives 249
- Silverbrook Research Pty Ltd 244
- CENTRE NATIONAL DE LA RECHERCHE SCIENTIFIQUE (CNRS) 241
- Bristol-Myers Squibb Company 236
- L'OREAL 235
- International Business Machines Corporation 211
- FUJIFILM CORPORATION 194
- L'Oréal 193
- IFP Energies nouvelles 180
- Centre National de la Recherche Scientifique (C.N.R.S.) 177
- Arkema France 172
- Merck Patent GmbH 164
- Novartis AG 161
- E. I. DU PONT DE NEMOURS AND COMPANY 151
- Microsoft Technology Licensing, LLC 143
- Genentech, Inc. 142
- L'ORÉAL 142
- Institut Français du Pétrole 138
- Gilead Sciences, Inc. 137
- Les Laboratoires Servier 136
- FUJI PHOTO FILM CO., LTD. 135
- INSTITUT NATIONAL DE LA SANTE ET DE LA RECHERCHE MEDICALE (INSERM) 133
- Intel Corporation 129
- Roquette Frères 129
- EASTMAN CHEMICAL COMPANY 128
- Human Genome Sciences, Inc. 128
- Sanofi-Aventis 127
- Agensys, Inc. 123
- Konica Corporation 123
- SANOFI 123
- EASTMAN KODAK COMPANY 122
- COMMISSARIAT A L'ENERGIE ATOMIQUE 122
- Dow Global Technologies LLC 116
- CIBA-GEIGY CORPORATION 115
- MICHELIN Recherche et Technique S.A. 113
- Intrexon Corporation 112
- Alnylam Pharmaceuticals, Inc. 110
- Borealis AG 109
- AT&T Intellectual Property I, L.P. 108
- Merck Patent GmbH 106
- Board of Regents, The University of Texas System 104
- Abbott Laboratories 102
- AstraZeneca AB 101
- Canon Kabushiki Kaisha 101
- SANOFI-SYNTHELABO 101
- BASF SE 100
- CENTRE NATIONAL DE LA RECHERCHE SCIENTIFIQUE 100
- F. Hoffmann-La Roche AG 97
- N.V. Nutricia 96
- Atofina 96
- CANON KABUSHIKI KAISHA 95
- Eastman Chemical Company 95
- The Procter & Gamble Company 95
- DOW AGROSCIENCES LLC 93
- 3M Innovative Properties Company 92
- IMMATICS BIOTECHNOLOGIES GMBH 88
- Centre National de la Recherche Scientifique (CNRS) 88
- BAYER AKTIENGESELLSCHAFT 87
- ARKEMA FRANCE 87
- Amgen Inc. 86
- Massachusetts Institute of Technology 86
- INSTITUT PASTEUR 85
- KONICA CORPORATION 84
- THE PROCTER & GAMBLE COMPANY 81
- Natera, Inc. 80
- THE REGENTS OF THE UNIVERSITY OF CALIFORNIA 80
- COMPAGNIE GENERALE DES ETABLISSEMENTS MICHELIN 79
- Shin-Etsu Chemical Co., Ltd. 77
- Rhodia Opérations 77
- Bayer Aktiengesellschaft 74
- Eli Lilly and Company 74
- Fujifilm Corporation 73
- Boehringer Ingelheim International GmbH 72
- Novozymes A/S 71
- SUMITOMO CHEMICAL COMPANY, LIMITED 71
- LES LABORATOIRES SERVIER 70
- SOCIETE DES PRODUITS NESTLE S.A. 70
- Colgate-Palmolive Company 69
- INTERNATIONAL BUSINESS MACHINES CORPORATION 68
- E. I. du Pont de Nemours and Company 67
- Michelin Recherche et Technique S.A. 67
- ELI LILLY AND COMPANY 66
- Fuji Photo Film Co., Ltd. 66
- Duke University 65
- E.I. DU PONT DE NEMOURS AND COMPANY 65
- ExxonMobil Chemical Patents Inc. 65
- Hoffmann-La Roche Inc. 65
- Monsanto Technology LLC 65
- Pfizer Inc. 65
- PIERRE FABRE MEDICAMENT 65
- ACCENTURE GLOBAL SOLUTIONS LIMITED 64
- Samsung Electronics Co., Ltd. 63
Страна публикации %
- US 82270
- WO 74434
- EP 38305
- JP 2338
- DE 1108
- FR 523
- SU 309
- GB 287
- CH 248
- MD 139
- RU 139
- CA 126
- EA 31
- UA 19
- AU 13
- UZ 6
- CN 2
- KZ 2
- KR 1
- OA 1
Код вида документа %
- A1 133715
- B1 31171
- A2 14773
- B2 14711
- A 2521
- A9 906
- A3 878
- E1 338
- B9 271
- C2 141
- T5 134
- A4 124
- B4 119
- G2 111
- A5 84
- U1 64
- C 59
- A8 58
- C1 51
- B3 41
- T3 7
- S1 6
- U 4
- F1 3
- H1 3
- B8 2
- A6 1
- I4 1
- P1 1
- P2 1
- T2 1
- T9 1
Дата публикации Применить Сбросить Дата подачи заявки Применить Сбросить МПК %
- A61P35/00 7608
- C12Q1/68 5861
- A61K38/00 4699
- A61K39/395 4322
- A61K39/00 4044
- C12N15/09 3642
- A61K9/00 3596
- A61K48/00 3074
- A61P43/00 3050
- C07K16/28 2918
- A61P29/00 2711
- A61K45/06 2576
- G01N33/68 2559
- G01N33/53 2526
- A61P25/00 2486
- C07K14/47 2327
- A61P9/00 2288
- C12N5/10 2261
- A61P25/28 2256
- C07D471/04 2171
- G01N33/50 2168
- C07H21/04 2034
- A61K38/17 1982
- A61P31/04 1934
- G06N20/00 1920
- C12N15/82 1874
- C12N1/21 1871
- C07D487/04 1779
- A61Q19/00 1748
- A61P9/10 1696
- G01N33/574 1656
- C07D401/12 1635
- C07D401/14 1585
- C12P21/02 1562
- C07K16/18 1486
- A61K47/48 1485
- A61P3/10 1468
- C07K14/705 1433
- A61P17/00 1383
- A61P11/00 1360
- A61P37/00 1355
- A61P31/12 1249
- A61K9/08 1219
- A61P31/00 1208
- C07D401/04 1186
- A61K31/00 1168
- A61K8/00 1166
- G01N33/569 1166
- H01L51/00 1164
- A61K45/00 1111
- G06N3/08 1096
- B60C1/00 1092
- A61K31/519 1079
- C12N15/113 1079
- C09K11/06 1077
- A61K9/20 1040
- C07D413/14 1036
- A61K31/5377 1028
- C07K14/00 1024
- C07K16/00 1014
- A61P3/00 1007
- A61K38/16 990
- C12N15/63 983
- G06K9/00 980
- A61K8/49 978
- A61K31/4439 963
- H04L29/06 953
- C07D403/12 951
- G06K9/62 944
- A61K9/16 932
- C07D405/12 930
- A61K31/44 918
- C07D417/14 905
- C12N15/11 904
- A61K31/496 892
- C12N15/12 891
- A61K31/506 865
- C07D417/12 864
- C07D405/14 863
- C12N7/00 848
- C12N5/06 843
- C12N1/20 837
- C07D413/12 834
- A61Q19/08 830
- A01H5/00 823
- A61K8/97 807
- A01N43/40 802
- H01L51/50 794
- C12N1/19 790
- A61K47/10 789
- A61K39/12 784
- C07K7/06 782
- C07K16/30 767
- C07B61/00 766
- A61K31/437 765
- A61P1/00 765
- A61B5/00 757
- C12P21/08 757
- A61P19/02 750
- C12N5/00 742
Группы %
- A61K31 26301
- C12N15 13656
- A61K38 11978
- G01N33 11618
- C07K14 11320
- A61K39 10401
- C12Q1 9507
- A61K9 8791
- A61P35 7942
- C07K16 7753
- C12N5 6930
- A61K47 6543
- C12N9 5934
- A61P31 5434
- A61P25 5220
- A61K8 5169
- C12N1 4111
- A01N43 3986
- C07D401 3947
- A61P9 3904
- A61K35 3879
- A61K45 3705
- A61P37 3431
- A61P3 3404
- C12P21 3336
- A61K48 3074
- A61P43 3060
- C07H21 2957
- C07D471 2892
- A61P29 2758
- C07D413 2665
- A61Q19 2555
- H01L51 2550
- C07D405 2546
- C07D403 2543
- A61P17 2497
- C07D487 2491
- C08K5 2422
- C07D417 2388
- G06N20 2161
- A61P1 2084
- G06K9 2059
- C08K3 2043
- B01J23 2036
- C12R1 1999
- A61P11 1941
- G03F7 1926
- C07D409 1863
- C07K7 1852
- C07D213 1835
- C07F9 1803
- G06N3 1782
- A61Q5 1734
- A23L1 1692
- H04L29 1689
- C08F4 1671
- C09K11 1654
- A61K36 1638
- G06F17 1569
- C11D3 1563
- A61P19 1555
- A61B5 1541
- C07D209 1483
- A01N25 1477
- C12N7 1473
- B01J37 1450
- A61P7 1391
- C08F2 1330
- C07D307 1327
- B01J20 1283
- G01N21 1248
- A01N37 1247
- C12P19 1247
- C07K1 1245
- G06F9 1245
- B01J35 1235
- C07F7 1221
- C07D239 1185
- C12P7 1184
- H01M4 1182
- A61L27 1169
- C08L23 1166
- G06F16 1166
- G06F3 1153
- C08F10 1136
- H04L12 1123
- B60C1 1110
- A61P27 1103
- A61P13 1092
- A61K49 1090
- A61K33 1076
- C07D207 1057
- A01H5 1038
- C07C69 1019
- C07D491 1017
- C08J5 1011
- B01J31 994
- C08J3 978
- B01J29 969
- C07D233 967
Подклассы %
- A61K 54995
- A61P 26068
- C12N 22294
- C07D 20062
- C07K 18516
- G01N 14231
- C07C 10257
- C12Q 9530
- G06F 8168
- A01N 7620
- B01J 7089
- C08L 6815
- C12P 6556
- C08F 6488
- C08G 4994
- A61Q 4737
- C07F 4680
- H01L 4607
- C07H 4499
- G06N 4468
- H04L 4434
- C08K 4248
- C09K 3695
- A23L 3160
- B01D 3006
- C08J 2915
- A61L 2858
- C01B 2838
- C09D 2789
- A61B 2706
- G06K 2514
- H01M 2217
- A61M 2212
- G06Q 2164
- C11D 2077
- G03F 2069
- C12R 2066
- G06T 1685
- C10G 1644
- B32B 1643
- A01P 1564
- A61F 1510
- H04B 1446
- H04W 1435
- B60C 1428
- A01H 1398
- H04N 1351
- C07B 1325
- G02B 1318
- B65D 1294
- G03C 1280
- C02F 1250
- A01K 1230
- B29C 1224
- C07J 1224
- C04B 1212
- C12M 1094
- C08B 1061
- C09B 1018
- C01G 919
- G16H 879
- C10M 877
- G10L 837
- C23C 822
- C09J 818
- C09C 816
- H01B 797
- C10L 747
- H05B 730
- B01F 724
- D21H 721
- B01L 710
- B82Y 710
- A23K 701
- H04M 683
- H04Q 677
- B41J 673
- A23C 669
- C40B 663
- C01F 656
- D06M 648
- B05D 639
- G01S 613
- A61N 612
- C03C 577
- G05B 537
- G02F 510
- B41M 503
- E21B 500
- H01J 498
- H03M 494
- G01R 490
- G03G 478
- C22B 457
- G11B 447
- D01F 441
- A61J 430
- C08C 416
- G05D 412
- B61L 402
Индексы CPC %
- A61K38/00 5096
- A61K45/06 3606
- A61K2039/505 2044
- C07D471/04 2018
- G06N20/00 1800
- C07D401/12 1701
- A61K39/00 1688
- C07K2319/00 1684
- A61K48/00 1555
- A61K9/0019 1532
- C07D487/04 1479
- C07K14/005 1455
- C07D401/14 1386
- A61Q19/00 1315
- C07K14/47 1299
- C12Q1/6886 1237
- C07D405/12 1112
- C07D401/04 1076
- B82Y30/00 1021
- C07D403/12 1021
- C12N7/00 1008
- C07D413/14 1005
- C07D417/12 995
- C12Q2600/158 992
- C07K16/18 968
- C12Q1/6883 944
- C07D417/14 925
- C07D413/12 921
- C07D405/14 900
- C12N15/86 872
- A23V2002/00 840
- C07K2317/24 837
- G06N3/08 812
- C07K14/705 808
- C07K2317/76 799
- C08F10/00 791
- A01K2217/05 775
- C07K2317/92 750
- C12Q2600/156 727
- C07D409/12 726
- A61Q19/08 725
- C12N15/113 693
- C09K11/06 670
- C12N2310/14 667
- C07J75/00 631
- C07D409/14 630
- A61K39/0011 622
- A61K31/00 592
- C07K2317/34 574
- C07D403/04 569
- C07C2101/14 568
- C07K7/06 565
- C07K2317/565 543
- A61P35/00 541
- G01N33/6893 531
- C07D401/06 530
- A61K31/5377 526
- C07K2317/21 524
- A61K47/10 523
- A61Q17/04 517
- B82Y5/00 484
- A01N43/40 481
- C07D403/14 480
- G03F7/0397 475
- A61K8/97 473
- A61K39/39 472
- A61K47/26 469
- Y02E10/549 465
- C01P2006/12 449
- A61K39/3955 440
- A61K2039/53 432
- G03F7/0045 431
- A61K38/1709 427
- C07K2319/30 426
- C12Q2600/106 424
- A61K39/12 422
- A61K31/519 416
- A61K31/496 415
- G06N5/04 412
- A61Q5/02 408
- C07D231/12 406
- A01N43/90 404
- C07K16/30 393
- C07D405/04 391
- A61K31/4439 390
- C07K14/415 382
- C07D495/04 371
- C07D413/04 366
- G01N2800/52 352
- C07K7/08 345
- C07K14/4748 342
- C07D417/04 336
- C07K16/28 330
- C07D409/04 323
- C07K2317/56 312
- C07K2317/622 305
- C08F210/16 305
- A61K9/0014 304
- C01P2004/61 296
- A61K31/506 293
Группы CPC %
- A61K31 12091
- C07K14 10453
- A61K38 9719
- G01N33 7886
- C12N15 7228
- A61K9 6267
- C12Q1 5776
- A61K39 5552
- C07K16 5480
- A61K2039 4994
- C12N9 4772
- A61K47 4491
- A61K8 3972
- A61K45 3636
- C07D401 3456
- C07K2317 2984
- C07K2319 2972
- C07D471 2584
- C07D405 2495
- G01N2333 2489
- Y10T428 2429
- A01N43 2360
- C07D413 2242
- C12N5 2208
- C07D417 2185
- A61Q19 2174
- C12Q2600 2133
- C07D403 2123
- G06N20 1958
- C07D487 1954
- A61K35 1906
- C08K5 1880
- A61K48 1849
- C07D213 1810
- C07D409 1798
- G01N2800 1788
- A23L1 1735
- H01L51 1718
- G06K9 1688
- C07F9 1686
- A61K2800 1660
- C12N2310 1431
- G03F7 1410
- B01J23 1404
- G06N3 1397
- A61Q5 1373
- C08K3 1356
- Y10S514 1293
- C07D209 1287
- C07D307 1205
- B01J37 1201
- C07K7 1174
- G06F16 1148
- C11D3 1123
- C07C2101 1107
- C07D231 1075
- G06F3 1066
- B01J35 1056
- C08F10 1056
- A61B5 1026
- C07D239 1026
- B82Y30 1008
- G06F17 1008
- C07D233 1005
- A01K2217 977
- G01N2500 975
- C12N7 973
- A61K36 964
- G06F9 963
- C07D333 953
- C07F7 938
- C09K11 936
- Y10S435 931
- C12N2501 910
- G06N5 899
- C07D295 897
- C01P2006 891
- C07D207 890
- G06F21 888
- A61L27 875
- C07D491 871
- C12P7 871
- C12N2710 861
- C07D277 859
- B01J20 837
- A23V2002 818
- C01P2004 814
- Y02E60 810
- A61K49 770
- A01N25 760
- C07D211 758
- A61Q17 753
- A01N37 747
- G06Q30 743
- C07K5 719
- H04L67 716
- G06Q10 696
- B01J21 692
- Y02E10 691
- A61K33 688
Подклассы CPC %
- A61K 33939
- C07D 16124
- C07K 15774
- C12N 14452
- G01N 10301
- C07C 8635
- Y10S 7709
- G06F 6415
- C12Q 5809
- Y10T 5604
- B01J 5016
- A01N
 Вконтакте
Вконтакте  Телеграм
Телеграм  YouTube
YouTube